摘要:
...
摘要:
... 当地时间8月5日,OpenAI推出自GPT-2以来的首批开源权重语言模型gpt-oss-120b与gpt-oss-20b,性能堪比o4-mini和o3-mini,可在高端笔记本和手机上运行。
OpenAI重新拥抱开源,该公司表示,发布开源系统的部分原因是,一些企业和个人更倾向于在自有计算机硬件上运行这类技术。“开源模型与我们的托管模型形成互补,为开发者提供了更丰富的工具选择。”这有助于加速推进AI前沿研究,降低新兴市场、资源受限行业及小型组织的使用门槛。
OpenAI总裁、创始人之一的格雷格·布罗克曼(Greg Brockman)说,“如果我们提供一款模型,人们就会用我们的技术。他们会依赖我们实现下一次突破。他们会给我们反馈、提供数据,以及改进模型所需的各种信息。这有助于我们取得进一步的进展。”
推出开源模型,可在手机运行
gpt-oss模型是OpenAI自2019年推出GPT-2以来发布的首批开源权重语言模型。OpenAI表示,gpt-oss-120b与gpt-oss-20b突破开源权重推理模型的边界,在推理任务上的表现优于同规模开源模型,能以低成本实现实际应用性能,经过优化可在消费级硬件上高效部署。模型训练过程结合了强化学习技术,并借鉴了OpenAI的o3和其他前沿内部模型。
gpt-oss模型使用预训练和后训练技术,注重推理能力、效率以及在各种部署环境中的实际可用性。每个模型都基于Transformer,利用混合专家(MoE)技术减少处理输入所需的激活参数数量。gpt-oss-120b每token激活51亿参数,gpt-oss-20b每token激活36亿参数,两款模型的总参数分别为1170亿和210亿。它们采用交替的密集型和局部带状稀疏注意力模式,类似于GPT-3。使用旋转位置编码(RoPE),支持长达128k上下文长度。两款开源模型支持低、中、高三种推理强度,可在延迟和性能之间权衡,开发者只需在系统消息中用一句话就能设置推理强度。
OpenAI CEO山姆·奥特曼表示,gpt-oss的性能堪比o4-mini,而且能在高端笔记本上运行,更小的版本能在手机上运行。“不久的将来,会有一种比你认识的最聪明的人还要智能的东西,在你口袋里的设备上运行,随时随地帮你解决各种问题。这真的是一件非同凡响的事。”
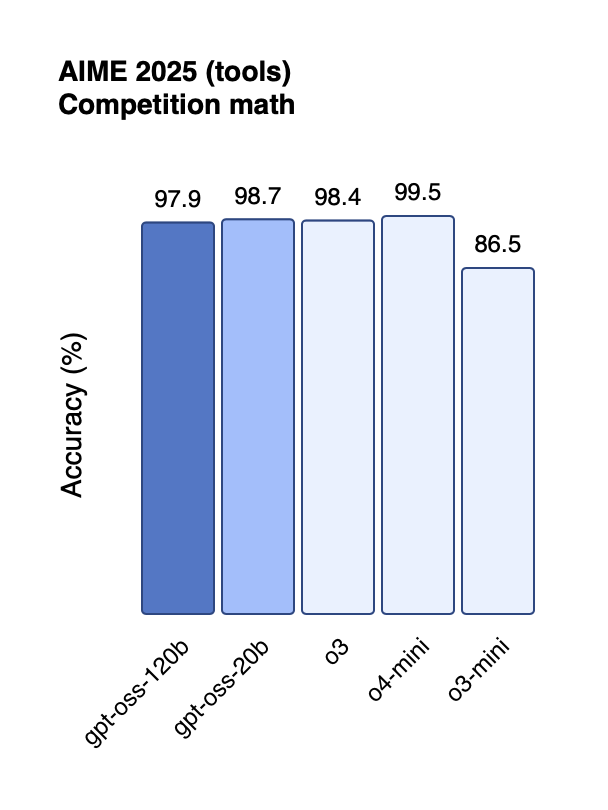
gpt-oss-120b与gpt-oss-20b在竞赛数学方面的性能。
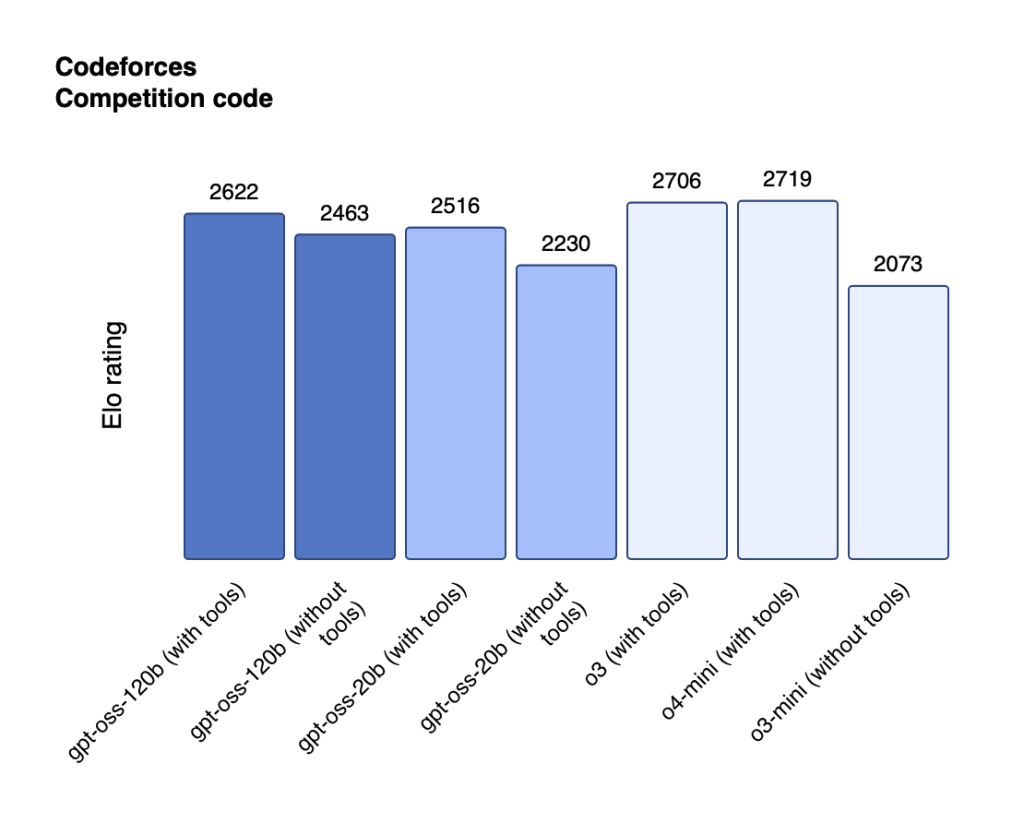
gpt-oss-120b与gpt-oss-20b在竞赛编程方面的性能。
gpt-oss-120b模型在核心推理基准测试上与OpenAI o4-mini几乎持平,能在单张80GB GPU上高效运行。在竞赛编程(Codeforces)、通用问题解决(MMLU和HLE)以及工具调用(TauBench)方面,gpt-oss-120b的表现优于OpenAI o3-mini,达到或超过了OpenAI o4-mini。在健康相关查询和竞赛数学方面,它的表现甚至比o4-mini更好。gpt-oss-20b模型在常见基准测试中的结果与OpenAI o3-mini相当,甚至在竞赛数学和健康相关查询方面的表现甚至超过了o3-mini,仅需16GB内存即可在边端设备上运行。
OpenAI为何重新拥抱开源
三年前,OpenAI推出ChatGPT并引发人工智能热潮,其后,OpenAI的技术大多处于保密状态。其他公司则通过“开源”共享技术,抢占OpenAI的市场份额。尤其是DeepSeek的出现,在全球范围内掀起了新的开源浪潮。如今,OpenAI重新拥抱开源,希望借此平衡竞争环境,确保企业和其他软件开发者继续使用其技术。OpenAI表示,发布开源系统的部分原因是,一些企业和个人更倾向于在自有计算机硬件上运行这类技术。
“开源模型与我们的托管模型形成互补,为开发者提供了更丰富的工具选择。”OpenAI表示,这有助于加速推进前沿研究,迸发创新活力,在各类应用场景中推动更安全透明的AI开发。这些开源模型还降低了新兴市场、资源受限行业及小型组织的使用门槛。
近期的研究表明,只要模型未接受过针对思维链对齐的直接监督训练,监控推理模型的思维链就有助于检测不当行为。OpenAI表示,两款gpt-oss模型的思维链均未接受任何直接监督,而这对于监控模型的不当行为、欺骗性输出和滥用风险至关重要。发布两款带有非监督式思维链的开源模型,能为开发者和研究人员提供机会,以便他们研究并构建自己的思维链监控系统。由于思维链可能包含幻觉信息或有害内容,因此开发者不应在其应用中直接向用户展示思维链内容。
为了确保模型的安全性,在预训练阶段,OpenAI过滤掉了与化学、生物、放射和核相关的特定有害数据,在后训练中运用审慎对齐和指令层级技术,教会模型拒绝不安全的提示词,并防御提示词注入攻击。开源模型发布后,攻击者可能会出于恶意目的对模型进行微调。为评估这类风险,OpenAI针对特定的生物学和网络安全数据对模型进行微调,模拟攻击者的方式,为每个领域创建了一个特定领域的 “不拒绝”版本,并通过内外部测试评估这些模型的能力水平。测试表明,即便使用OpenAI行业领先的训练堆栈进行了微调,这些经过恶意微调的模型仍无法达到高能力水平。
OpenAI表示,这些流程标志着开源模型的安全性迈出了有意义的一步,“我们希望这些模型能帮助推动整个行业的安全训练和对齐研究。”为构建更安全的开源生态系统,OpenAI发起奖金50万美元的“红队挑战”,鼓励来自世界各地的研究人员、开发人员和爱好者帮助识别新的安全问题。
开源与闭源的辩论一直存在,企业的策略也在调整。与OpenAI拥抱开源不同,Meta或将转向更保守的闭源软件策略。Meta新近成立超级智能实验室后,实验室一小批高级成员讨论放弃该公司最强大的开源人工智能模型Behemoth,转而开发闭源模型。