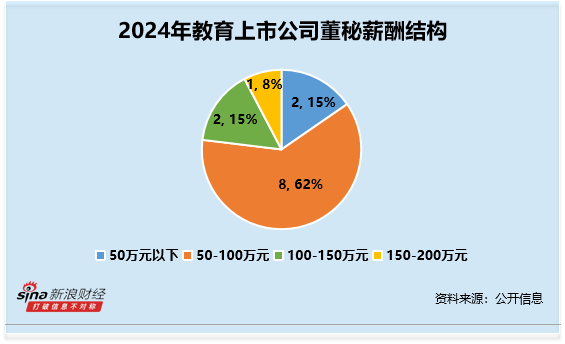
摘要:
...
摘要:
...
“2025世界大会”于8月8日至12日在北京经济技术开发区开幕,“AI 大模型赋能机器人与具身智能产业新范式交流活动”作为2025世界机器人大会的专题活动于8月8日同期召开。自变量机器人创始人兼CEO王潜出席并演讲。

以下为演讲实录:
大家好!非常荣幸,今天论坛的主题是大模型赋能具身智能。机器人已经是一个非常古老、大概有接近100年历史的行业,从阿西莫夫提出三定律开始到现在差不多80多年的时间。
为什么大家今天探索机器人自主操作,确实是大模型带来了巨大的变化,这个变化不仅指语言模型、多模态模型的成果,更多的还是方法论、思维方式上的转变,我们相信具身智能大模型可以走到类似于今天语言模型的阶段,机器人可以通用、泛化,能够做到各种各样复杂的任务和操作。
过去,市场上认为自变量是做具身大脑、大模型的公司,实际上我们现在也是软硬一体,直接面向消费者销售软硬一体整个产品的公司,在这次的WRC发布了全新自研本体,欢迎大家去我们的展台交流。
历史上做通用机器人主要还是围绕四个大方向:一是locomotion,从走路、跑步、跳舞到各种各样的肢体运动;二是navigation导航,自动驾驶做了很多探索;三是和人交互,和人说话,能够理解人的意图并给人反馈,在这三个方向,基于过去的诸多探索,成效颇丰,但其中最难的也是最有用的就是manipulation:手部操作,这也是我今天演讲的题目——基于具身智能大模型,构建可精细操作的通用机器人,这的确是整个行业最主要的卡点。
这是不是因为硬件的问题呢?其实不是,更广义地来说,整个机器人行业发展的问题都不是因为硬件,过去80年里,围绕硬件做了大量工作,理论上已经可以完成非常精细和复杂的操作,比如用手术机器人,甚至可以超过人类医生的水平,但问题就在于机器人不能自己去做,这里面最核心的还是AI问题。
所以这也是我刚才提到为什么大模型给行业带来了新的变化,而不是某一个零部件或者其他,是AI实际意义上推动了整个领域的所有发展。
但我们并不能认为直接用语言模型或者多模态模型就可以解决manipulation问题,机器人的模型或者说具身模型应该是独立于、完全平行于数字世界的基础模型,是语言模型之外的另一大模型。
当前大家的认识相对比较有限,特别是来自其他行业的人员,还是会认为直接将DeepSeekR1或者Chat GPT等大语言模型,搭载在一个很好的人形机器人上,就能处理物理世界中的问题。
实际上,物理世界和数字世界有巨大鸿沟和差异,在具身智能领域所碰到的大量事情没办法只凭借数字世界的方法和手段解决。核心点在于物理世界的随机性太高,产生了大量和语言模型、Locomotion、Navigation等领域的不同,的确需要物理世界单独的模型来应对。
数据方面,走路这件事情可以用仿真做,手上操作更多的还是要依靠真实世界的数据。物理世界中大量的接触、随机性的引入,使得仿真数据和现实世界的Gap非常大。为什么一定要做端到端,也是因为大量的随机性、物理接触所导致,如果用分层模型,前面层里面发生的错误和误差会非常快速地累积和爆炸,所以需要端到端具身智能基础模型。
今天行业也走到了数据驱动的概念上,用更多的数据、更多的算力、更好的模型专门针对机器人操作训练。但并不是简单的数据多就足够,核心还是更多在于数据质量、数据来源。
对比语言模型,我们并不缺乏语言的数据,但是一直到差不多GPT3时,才看到智能表现的曲线有了大幅度提升。和GPT3同时代的很多研究者都在训相当规模的模型,规模甚至可能比GPT3更大,使用的数据量也足够多,但只有GPT3,到后面Chat GPT获得了比较好的水平。其中最核心的点还是怎么筛选数据、使用数据。
所以以数据为中心不只是简单地把数据量变得更大,其中更重要的点还是要提升数据的质量、数据的多样性等。以前做模型更多的还是在模型本身,更好的算法、更好的模型架构、更好的训练方法,但是今天大部分的Know-How、大部分的工作集中在数据上,这才叫做以数据为中心。
刚才聚焦怎么让大模型服务于机器人,但反过来为什么要做大模型、为什么要做人工智能?最终是为了实现通用人工智能AGI。机器人是通向通用人工智能必不可少的一步,除了让AI帮助机器人具备智能外,也要让机器人帮助AI往前更进一步,这也是自变量非常希望做的事,也是通用人工智能的必由路线。
不管是语言还是多模态,还是具身,数据已经基本上被用尽。互联网的数据,到目前为止,高质量的数据已经完全被用尽了,低质量的数据基本上未来在2-3年里也会被耗尽的,所以今天需要更多的大量使用人造的数据。
其实我们身边就是一个巨大的数据源,所有的物理世界、现实世界的数据来源是无穷无尽的,但这些数据需要一个实际的硬件本体,承载它进行各种各样的体验和探索,之后数据也能通过采集获取。所以这是和大语言模型的本质区别,从这个意义上来说,机器人应该是所有的基于身体体验的智能,本质是智能体。
目前大部分的机器人模型还是感知是感知、规划是规划、行动是行动,所以更多的是接近于以前的做法:首先要理解世界,基于世界再规划行动。但其实人类不是这样做的,人类是有大量的探索、大量的反馈,根据行动训练感知。例如前方有一个东西挡住去芦,人是会将其挪走或者绕开它,另外一些未知的事情自主去尝试,未知的错误用新的方法修正。
所以具身智能应该是一个完整的闭环:一是理论上不应该是单纯的语言模型应用,二是即使是物理世界的模型,也应该是完整的闭环。
但物理世界的基础模型,其复杂性更多在于冰山一角海面下的部分,很难通过已有的虚拟世界发展而来。更多的预训练模型、语言模型包括视觉模型,都很难准确地描述物理过程的发生。哪怕简单地开一个瓶盖,都很难用语言详细地描述一二三四五哪些步骤,做了哪些动作,使用了哪些力。更进一步即使有图像,由于大量的遮挡、大量的最低性能,也很难替代动作模态。
物理世界中的基础模型还是需要单独的统一学习范式,自变量在这一领域也做了大量的工作。整个感知规划行动,端到端的feedback,所有的已知数据来源,非常大的开源数据集,互联网上的数据,再到现实世界直接收集到的数据,通过强化学习或者其他的后训练,我们也还研究COT的Post-training(后训练)工作。
很多Post-training(后训练)往往是调一个语言模型,然后在上面接API,做某一个单独动作的API,但真正要做物理现场的任务,以及非常复杂和困难的任务,还是需要原生的COT、原生的多模态模型,自变量从输入语言、视觉、触觉等信号,再到输出动作,同时也包含语言、视觉,可以构造输出的内容再直接输回去,形成非常长甚至任意长的思维链工作。
我们展台也展示了多项长序列复杂任务。自变量自研的VLA模型目前在全世界范围内能够完成最困难、最长程的任务,实现高级别的泛化性。在任务难度上能够做到扣扣子、拉拉链;在泛化性上,除了位置、光照、环境的泛化,在更高级别,如同一个任务、不同的被操作物体,甚至不同的任务、全新的没有见过的任务,任意长度的长程的推理和规划,自变量都有很好的实现。
对比人类的学习方式,人针对问题会探索各种各样不同的解法,听上去很像强化学习,但实际上并不是,人在开放环境中的探索超越了单一任务的强化学习。如观察不完全的情况,有遮挡的情况、环境中各种各样的干扰,人是可以通过动作把感知耦合在一起的,但过去不管是机器人还是AI均缺乏这方面的能力。所以需要下一步——体验学习。
体验学习在机器人上是完美的落地场景,对模型训练有巨大的帮助。加上物理世界是天然的环境场景,已有的大规模预训练包括强化学习,都可以在其中完成,并且强化学习更进一步可以做自动的场景生成,自动场景恢复,将整个环路完全闭环。在更加开放的场景中做多任务的强化学习、多任务的自主探索,这也是自变量目前努力探索的下一步。
简单总结,第一,我们需要单独的物理世界基础模型,最终形成所追求的真正意义上的通用人工智能和通用机器人。最核心的点还是在于物理世界是所有智能的起点,也是最终所有智能的终点。
谢谢大家。
新浪声明:所有会议实录均为现场速记整理,未经演讲者审阅,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。