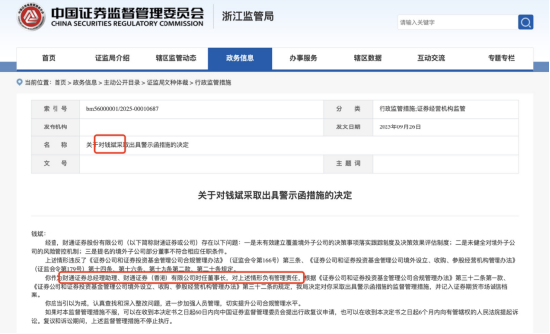
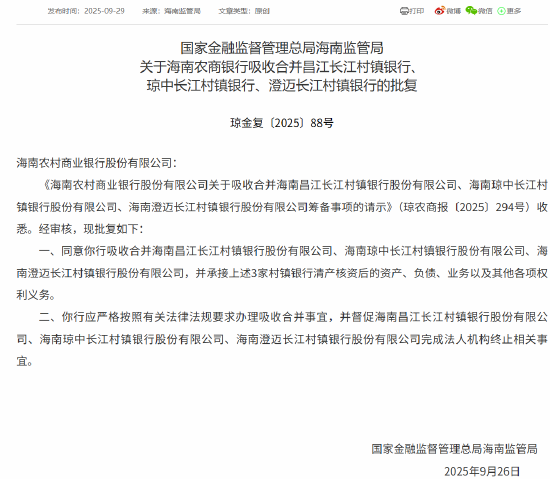
摘要:
...
摘要:
... 当前,大模型通用能力与行业深度需求之间的适配矛盾日益凸显,智能体开发面临技术、应用、成本、数据等挑战。9月29日,在由上海科学技术交流中心与上海市杨浦区科技和经济委员会联合主办的“大模型技术应用落地系列沙龙”中,高校专家提出新的优化路径。
上海工程技术大学副教授黄勃解析了面向图模互补的智能体开发与研究,为跨模态知识融合提供新思路,以图模互补支持更可信、语义更丰富的智能体能力。

上海工程技术大学副教授黄勃。
图模型是以结构化关系构建可解释的知识网络,支撑复杂系统中的逻辑推理和决策分析。它以节点与边的网络为载体,将零散信息转化为结构化、可计算的知识,既保留直观语义的表达属性,又具备数学严谨的推理特性,是解析复杂系统的核心工具。但图模型知识更新滞后,语义理解薄弱。它依赖人工维护,难以实时扩展,知识更新周期长,无法自动获取新知识,也无法处理模糊语境和一词多义现象,难以理解隐含语义、隐喻和比喻,缺乏上下文感知能力。
图模型这些局限正可以由大语言模型补足。大模型通过海量文本学习语义表达,实现自然语言理解和生成的革命性突破,通过上下文建模可有效处理语义歧义与指代问题。作为人机交互桥梁,大语言模型将非结构化语言转化为可操作的语义,成为通向通用人工智能的重要入口。尽管大语言模型存在幻觉问题、结构化推理弱、黑箱决策等痛点,图模型却可以补足这些缺陷。
黄勃表示,图提供结构化约束与推理路径,大语言模型提供语义理解与自然语言接口,以图模互补支持更可信、语义更丰富的智能体能力。在这种融合中,图增强策略可以利用结构化知识为大模型提供事实支撑与约束,提升回答的精确性和可解释性;大模型增强图谱策略利用大模型从大量非结构化数据中抽取、补全与修正知识图谱,降低人工维护成本并提升覆盖。
上海大学副院长骆祥峰聚焦面向大模型微调的知识生成方法研究,探讨模型优化的核心技术路径。自动控制类小模型决策速度快、精度高、建构快,但泛化能力弱,只适应确定环境;强化学习类中模型决策速度快、泛化能力强,但训练慢,难以理解复杂任务;大模型泛化能力强,具有丰富的常识,善于决策,但决策速度慢,幻觉问题突出。
骆祥峰表示,目前缺乏大中小模型协同决策的能力,缺乏复杂任务的分解能力,缺乏智能生成智能体自动化管理训练部署能力。因此他提出要面向大模型决策的知识生成,构建无人系统决策知识生成平台,其中包括场景任务分解大模型、数据生成大模型、单平台高层规划大模型,以大中小模型联合训练,实现智能体应用部署。
本次沙龙是2025年长三角高技术成果交易会的首场预热活动。沙龙以“数据赋能与知识工程”为核心主题,紧扣“数据+模型”双轮驱动核心,围绕RAG(检索增强生成)技术实践、知识图谱与大模型融合、行业数据库构建、多模态数据处理四大前沿方向展开深入研讨,旨在打通数据资产向知识价值转化的关键路径,为大模型技术落地扫清数据层面的核心障碍。据悉,2025年长三角高技术成果交易会将于10月20日至11月20日举行,其间还将举办多场技术沙龙,持续推动大模型等前沿技术从研发端走向产业端,助力长三角区域科技创新与产业升级。