
 摘要:
...
摘要:
... 炒股就看,权威,专业,及时,全面,助您挖掘潜力主题机会!
来源:证券研究

国内半导体设备自给率处于低水平且国产设备主要应用在成熟制程,国产化需求仍然十分强劲,华为等终端厂商对国内半导体供应链的催熟、升级迭代将带来积极作用,头部优质设备企业将承担更多攻坚任务,空白环节的“0-1”突破以及重要环节的国产化率提升将带来重要的投资机会。
AI及AI+开启算力时代,硬件基础设施成为发展基石,算力芯片等环节核心受益,先进封装和先进制程制造筑牢硬件底座。
中信建投证券通信、人工智能、电子及机械等研究团队推出【半导体产业链投资展望】:
半导体:商务部对美国产相关模拟芯片发起反倾销立案调查。美光宣布存储产品涨价并暂停报价。
商务部发布2025年第27号公告,对原产于美国的进口相关模拟芯片发起反倾销立案调查。中华人民共和国商务部(以下简称商务部)于2025年7月23日收到江苏省半导体行业协会代表国内相关模拟芯片产业正式提交的反倾销调查申请,申请人请求对原产于美国的进口相关模拟芯片进行反倾销调查。商务部依据《中华人民共和国反倾销条例》有关规定,对申请人资格、申请调查产品有关情况、中国同类产品有关情况、申请调查产品对国内产业影响、申请调查国家有关情况等进行了审查。根据上述审查结果,依据《中华人民共和国反倾销条例》第十六条的规定,商务部决定自2025年9月13日起对原产于美国的进口相关模拟芯片进行反倾销立案调查。本次调查自2025年9月13日起开始,通常应在2026年9月13日前结束调查,特殊情况下可延长6个月。
据台媒援引渠道消息报道称,存储厂商美光发出通知,全面停止DDR4、DDR5、LPDDR4、LPDDR5这些主力非HBM DRAM内存产品报价,暂停期暂定为一周,后续这些品类可能调涨20%~30%。据悉,美光接下来的这轮产品价格变动将覆盖几乎所有应用领域,消费电子、工业、车用类型的产品都将受到影响,个别品类的涨价幅度预计将达到70%;此次全线涨价的背景原因则是美光注意到客户的需求预测与实际供应能力间存在明显缺口。
风险提示:未来中美贸易摩擦可能进一步加剧,存在美国政府将继续加征关税、设置进口限制条件或其他贸易壁垒风险;宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险;全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。
02 商务部对原产于美国的进口相关模拟芯片发起反倾销调查
半导体:商务部公告2025年第27号 公布对原产于美国的进口相关模拟芯片发起反倾销立案调查,利好国内模拟IC企业。
商务部于2025年7月23日收到江苏省半导体行业协会代表国内相关模拟芯片产业正式提交的反倾销调查申请,申请人请求对原产于美国的进口相关模拟芯片进行反倾销调查。商务部决定自2025年9月13日起对原产于美国的进口相关模拟芯片进行反倾销立案调查。此次被调查产品主要包括相关模拟芯片中使用40nm及以上工艺制程的通用接口芯片(Commodity Interface IC Chip)和栅极驱动芯片(Gate Driver IC Chip)。
被调查的通用接口芯片包括
1.符合ISO11898标准的控制器局域网(CAN,Controller Area Network)接口收发器芯片,用于汽车及其他工业产品中各系统之间信号的发送与接收;
2.符合TIA/EIA-485标准的RS485接口收发器芯片,用于工业系统中各类设备之间信号的发送与接收;
3.基于利用串行数据线和串行时钟线的低速串行总线方式制得的双向二线制同步串行总线(I2C)接口芯片,用于设备中的各类板卡或芯片之间的信号缓冲中继通道的切换与扩展;
4.符合国际电工委员会IEC 60747-5-2标准的数字隔离器芯片,用于汽车及其他工业产品中高低压系统之间的绝缘通信,或用于增强通信抗干扰性能;
5.其他同时兼容上述种类的通用接口芯片。
被调查的栅极驱动芯片包括:
1.低边栅极驱动芯片;
2.半桥/多路栅极驱动芯片;
3.隔离栅极驱动芯片。海外以TI为代表的模拟IC大厂在过去几年开展价格战抢占市场份额,导致国内企业经营承压明显。江苏省半导体行业协会的数据显示,2022至2024年,申请调查产品自美进口量累计增长37%,进口价格累计下降52%。此次商务部反倾销调查有望降低国内模拟IC企业承受的竞争压力,并加速推进国产化进程。布局相关产品的国产模拟IC企业有望受益。
风险提示:未来中美贸易摩擦可能进一步加剧,存在美国政府将继续加征关税、设置进口限制条件或其他贸易壁垒风险;宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险;全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。
03 电子行业2025半年报综述:上半年业绩亮眼,下半年AI持续驱动增长
上半年消费电子和半导体持续复苏,在AI算力的进一步催化下,进入新一轮的双旺共振期,相应带动业绩持续向上。2025年上半年电子板块467家公司营业收入合计18578亿元,同比增长19.2%;归母净利润合计859亿元,同比增长29.0%。展望下半年及明年,消费电子旺季叠加端侧AI新品密集发布,国内外大厂AI相关资本开支指引积极,驱动电子行业基本面向好,加之创新升级、国产替代等各项利好催化,行业周期有望持续向上,整体配置价值凸显。
一、上半年整体业绩亮眼,收入利润双双实现高增
2025年上半年电子板块467家公司营业收入合计18578亿元,同比增长19.2%;归母净利润合计859亿元,同比增长29.0%。分季度看,自23Q4以来,消费电子和半导体先后实现周期底部反转,在AI算力的进一步催化下,进入新一轮的双旺共振期,相应带动业绩持续向上。25Q2电子板块营业收入合计9934亿元,同比增长20.3%;归母净利润合计487亿元,同比增长27.7%。盈利能力继续提升,毛利率为15.9%,环比提升0.1pct,期间费用率10.4%,环比减少0.7pct,研发费用率5.3%,环比减少0.2pct,净利率4.7%,环比提升0.4pct。
二、上半年电子板块有较大涨幅,机构持仓呈上升趋势
2025年1月初至2025年9月5日,申万累计涨幅32.0%,其中元件II(被动元件+PCB)板块涨幅最高,为86.6%。上半年电子板块估值呈上升趋势,截至2025年9月5日,整体PE-TTM为64.23倍,处于2019年以来的99.4%分位点。2021Q4公募基金电子行业持仓占比达到阶段性高点,此后逐季度呈下降趋势,直至22Q4有所反弹。2023年以来,公募基金电子行业持仓占比呈上升趋势,25Q2持仓占比为17.01%,环比上升0.03pct。持仓结构方面,半导体持仓/电子持仓比例环比下滑,25Q2达65.31%,环比下滑1.0pct。
三、AI驱动新一轮半导体周期,端侧更具爆发潜力
2023-2024年,AI需求集中在云端,大模型的迭代演进拉动算力基础设施需求快速增长,GPU、HBM 几乎一年迭代一个代际,配套的网卡、光模块、散热、铜缆/PCB等亦是如此。但当前,海外先进制造、先进封装代工产能难以获取,国产算力产业链仍在奋力追赶,关键环节处于“强需求、弱供给” 的状态。虽然国内半导体国产化率在过去几年持续提升,但是核心环节国产化率仍然较低,如高端芯片的生产制造、先进封装技术的研发、关键设备材料的攻关、EDA软件的开发等。在传统半导体国产化已有一定基础的情况下,先进制程、先进存储、先进封装、核心设备材料、EDA软件的国产化仍有较大提升空间。年初Deepseek发布R1,性能媲美OpenAI o1,并通过诸多优化手段实现了算力成本的大幅降低,成本降低为推理应用突破提供了基础。在云侧,随着大模型能力持续突破,AI在头部CSP的实际收入、用户行为和产品力提升方面也在深度介入。在端侧,移动设备的硬件升级、大模型的压缩技术等正在推动端侧模型落地。建议重点关注:
(1)半导体:算力供应紧张,AI有望引领下一轮周期成长。英伟达GB200、CSP自研ASIC放量,下一代GB300即将量产,同时HBM4/4e也将落地,算力硬件快速迭代。AI算力加速了对先进制程、先进封装、先进存储的需求,以GPU、CoWoS/SoIC、HBM、高速PCB、光模块为代表的算力需求持续扩张,供应商大力扩产,预计2025年AI硬件产业维持高景气。建议关注国内自主算力芯片及先进封装标的。
(2)消费电子:2025年第一季度全球智能手机出货量同比微增1.5%,达到3.05亿部,第二季度同比增幅降至1%,出货量2.95亿部,核心原因在于宏观经济疲弱、收入预期波动等抑制了消费者需求。中国市场在第二季度同样迎来了连续六个季度增长后的首次下滑,智能手机出货量同比下滑4%至6900万台。分品牌来看,中国市场华为份额时隔四年多重回榜首,苹果则有所下滑。展望全年,由于面临国际政治关系不确定、宏观经济表现疲软等因素,近期多家机构均下调2025年全球智能手机出货量预测。尽管手机市场表现一般,但是可穿戴市场如智能眼镜受AI赋能正迎来爆发增长阶段。2025年AI眼镜市场迎来多方玩家参与,新品频发,行业进入百镜大战。根据wellsenn XR数据,2025Q2全球AI眼镜销量87万台,同比增长222%,而下半年Meta、阿里、Rokid、三星、理想、谷东智能等品牌将陆续发布AI眼镜新品,刺激AI眼镜市场出货量迎来爆发增长,预计全年AI智能眼镜销量将同比增长135%至550万台以上。建议关注华为/iPhone产业链、折叠屏、AI眼镜。
(3)汽车电子:汽车智能化成为当前汽车发展的主旋律,引领智驾平权,高级别智驾需要更多数量的车载摄像头,同时也需要更高像素的配置,因此带来车载CIS量价齐升,其他如激光雷达等环节同样受益。
(4)PCB:增加PCB板层数、使用介质损耗更低的覆铜板(CCL)可以显著解决PCIe信号链路插损问题,因此传统服务器中芯片平台方案加速渗透带动PCB层数增加及CCL升级,我们认为,PCIe总线向高速演进将带动PCB规格持续升级,由M6(Df区间在0.004-0.008)及以上覆铜板材料制成的超过16层及以上的PCB逐渐成为服务器标配,未来将持续向M8覆铜板材料组成18层以上PCB升级。而在AI服务器中,由于AI服务器架构相对更复杂、性能要求更高,如相比传统服务器,AI服务器新增UBB母板、OAM加速卡增加HDI需求、CPU板组也有升级,因此单台服务器中PCB价值量较传统普通服务器会有明显的提升。TrendForce预估2024年全球服务器整机出货量约1365万台,年增约2.05%,将重回增长。对于AI服务器,Trendforce预估2023年全球AI服务器(包含搭载GPU、FPGA、ASIC等)出货量近120万台,占整体服务器出货量近9%,2024年AI服务器出货量占比将提升至约12.1%,未来三年年均复合增速高达25%。从短期来看,传统服务器出货逐渐复苏、AI服务器高速增长,服务器PCB市场未来景气高增。从中长期来看,人工智能、高速网络的强劲需求将继续推动高速高层等细分市场的增长,并为PCB行业带来新一轮成长周期,未来全球PCB行业仍将呈现增长的趋势。
投资建议
基本面角度,2025年行业主要受两大因素驱动:(1)AI算力成本降低催化行业推理需求,年初Deepseek发布R1,性能媲美OpenAI o1,并通过诸多优化手段实现了算力成本的大幅降低,成本降低为推理应用突破提供了基础。在云侧,随着大模型能力持续突破,AI在头部CSP的实际收入、用户行为和产品力提升方面也在深度介入。在端侧,移动设备的硬件升级、大模型的压缩技术等正在推动端侧模型落地。英伟达GB200、CSP自研ASIC放量,下一代GB300即将量产,同时HBM4/4e也将落地,算力硬件快速迭代。AI算力加速了对先进制程、先进封装、先进存储的需求,以GPU、CoWoS/SoIC、HBM、高速PCB、光模块为代表的算力需求持续扩张,供应商大力扩产,预计2025年AI硬件产业维持高景气。端侧AI带来成本、能耗、可靠性、隐私、安全和个性化优势,已经具备实践基础,终端设备有望在AI的催化下迎来新一轮创新周期。从终端看,先落地、成规模的终端是手机和PC,硬件上其2024年AI渗透率分别为18%、32%,预计手机AI化比率持续提升,持续推动硬件升级。此外,智能车、、可穿戴(XR、AI眼镜、耳机)、智能家居等也正在融入AI,2025-2026年有望看到终端出货的爆发式增长。(2)国产算力自给受限要求半导体更快国产替代,当前,海外先进制造、先进封装代工产能难以获取,国产算力产业链仍在奋力追赶,关键环节处于“强需求、弱供给”的状态。虽然国内半导体国产化率在过去几年持续提升,但是核心环节国产化率仍然较低,如高端芯片的生产制造、先进封装技术的研发、关键设备材料的攻关、EDA软件的开发等。在传统半导体国产化已有一定基础的情况下,先进制程、先进存储、先进封装、核心设备材料、EDA软件的国产化仍有较大提升空间。
市场角度,2025年1月初至2025年9月5日,申万电子指数累计涨幅32%,其中元件II(被动元件+PCB)板块涨幅最高,为86.6%。上半年电子板块估值呈上升趋势,截至2025年9月5日,整体PE-TTM为64.23倍,处于2019年以来的99.4%分位点。板块上涨主要是因为:(1)行业周期走出底部区间,存储等板块进入涨价阶段,板块业绩回暖向好;(2)人工智能技术创新催化,打开半导体硬件市场空间,算力相关板块估值水平大幅提升;(3)行业竞争逐步趋于良性,代工厂稼动率提升带动盈利能力提升。
展望下半年及明年,(1)消费电子需求恢复势头明显。苹果方面,苹果追加在美1000亿美元投资,同时,iPhone17新机有望搭载更多AI功能,首款折叠屏手机有望于明年推出,吸引消费者换购新机,产业链相关公司有望受益,同时果链估值处于电子板块内相对低位,具备重要配置价值。此外,安卓方面,光学升级、AI功能、散热等环节创新有望提升安卓品牌竞争力,国补政策也有效刺激消费者换机,而折叠屏手机领域预计随着明年苹果发布折叠屏手机有望引爆折叠机市场,安卓品牌凭借先发优势将同步受益,同时也将成为国内安卓品牌切入高端市场的重要契机,推动国内安卓品牌在高端智能手机市场获得份额提升,利好国内安卓供应链。建议关注:华为手机产业链、苹果产业链、折叠屏产业链、MR产业链、汽车电子产业链。
(2)行业需求逐步复苏,代工厂稼动率维持高位。下游需求逐步复苏,同时行业竞争逐步出清,带动功率等半导体公司年初以来稼动率维持高位;美国限制中国半导体产业发展成为长期趋势,产业链国产自主势在必行,华为积极推动核心零部件国产替代,此次Mate60系列回归标志着国产半导体产业链技术实力、生产能力的提升。先进工艺的发展需要领先设计厂商与制造端紧密配合,因此华为对国内半导体供应链的催熟、升级迭代将带来积极作用。长期看,国内晶圆厂扩产叠加国产化诉求将延续,国内半导体设备及零部件公司也将持续受益。建议关注国产化率仍有较大提升空间的晶圆代工、半导体设备及零部件环节。
(3)算力供应紧张,AI有望引领下一轮周期成长。英伟达GB200、CSP自研ASIC放量,下一代GB300即将量产,同时HBM4/4e也将落地,算力硬件快速迭代。AI算力加速了对先进制程、先进封装、先进存储的需求,以GPU、CoWoS/SoIC、HBM、高速PCB、光模块为代表的算力需求持续扩张,供应商大力扩产,预计2025年AI硬件产业维持高景气。建议关注国内自主算力芯片及先进封装标的。
整体来看,市场需求逐步回暖,库存水位不断趋于正常水平,整体业绩呈现边际改善,行业基本面向好趋势明显显现,加之创新升级、国产替代等各项利好催化,行业周期有望迎来向上区间,整体配置价值凸显。建议重点关注:
(1)半导体:关注人工智能需求增量及国产化进展。
a)设备、材料及零部件:国内半导体设备自给率处于低水平且国产设备主要应用在成熟制程,国产化需求仍然十分强劲,华为等终端厂商对国内半导体供应链的催熟、升级迭代将带来积极作用,头部优质设备企业将承担更多攻坚任务,空白环节的“0-1”突破以及重要环节的国产化率提升将带来重要的投资机会。此外,材料零部件领域国产替代也提上日程,设备层面的国产化有所突破后且半导体设备零部件以及制造所用的材料依旧被卡脖子,海外限制范围扩大后,材料、零部件的重要性提高,国产化加速。建议关注半导体设备、半导体零部件环节。
b)IC设计:看好AIOT、手机、服务器等终端修复带来的相关厂商业绩和估值修复,建议关注:存储器、内存接口、AIOT。
c)算力:AI及AI+开启算力时代,硬件基础设施成为发展基石,算力芯片等环节核心受益,先进封装和先进制程制造筑牢硬件底座。
(2)消费电子&汽车电子:
a)华为产业链:华为积极推动核心零部件国产替代,此次Mate60系列回归标志着有望带动国产手机产业链的业绩提升,建议关注卫星通信、射频、OLED屏幕、无线充电芯片、CIS等环节。
b)折叠屏产业链:折叠屏成为手机终端形态升级的重要路径,市场需求得到积极反馈,建议关注MIM零部件、铰链、柔性OLED显示模组等环节;
c)苹果产业链:秋季iPhone17备货积极,明年将推出首款折叠屏手机,有望引领新的一轮换机潮,相关产业链标的受益,建议关注钛合金中框、LIPO等手机创新环节以及光学、PCB、结构件、散热、组装等产业链环节;
d)汽车电动化/智能化:在5G以及万物互联时代,汽车成为除了手机之外最重要的智能终端,电动化与智能化趋势持续推进整车电子电气相关价值量提升。消费电子与汽车电子两大赛道融合大势所趋,消费电子基本盘稳固且汽车电子拓展顺利的公司有望迎来业绩与估值的修复。
e)AI眼镜产业链:多家品牌厂商发布AI眼镜新品,百镜大战有望引爆AI眼镜市场,建议关注代工、光学、SoC、Micro LED等环节。
风险提示:
1、宏观经济波动风险。受到全球宏观经济的波动、行业景气度等因素影响,半导体行业存在一定的周期性,如果宏观经济波动较大或长期处于低谷,居民收入、购买力及消费意愿将受到抑制,消费电子等下游市场需求的波动和低迷会导致半导体产品的需求下降,进而影响上下游产业链相关公司的经营业绩。
2、产业政策变化风险。电子尤其是半导体产业是我国的战略支柱产业,近年来国家层面出台一系列支持政策。在产业政策支持和国民经济发展的推动下,我国半导体行业整体的设计能力、生产工艺、自主创新能力有了较大的提升。如未来上述产业政策出现不利变化,将对行业的发展前景产生一定不利影响。
3、技术创新不及预期风险。由外部环境的不确定性、技术创新项目本身的难度与复杂性、创新者自身能力与实力的有限性,而致技术创新活动达不到预期目标。由于算力芯片、IP等产品市场技术壁垒高,行业龙头不断研发创新,未来若国内公司研发进展不及预期,致新一代产品开发进度、性能等指标不及预期,则会影响其市场竞争力。
4、中美贸易/科技摩擦升级风险。半导体产业主要生产设备和原材料有较大部分向境外供应商采购,未来不排除中美贸易摩擦可能进一步加剧、美国加大对中国半导体行业的遏制、设置进口限制条件或其他贸易壁垒的可能性,从而导致部分公司面临设备、原材料供应发生变动等风险,正常生产活动受到一定的限制,进而对公司的业务和经营产生不利影响。
5、国产化进度不及预期风险。当前半导体设备、材料、零部件、高算力芯片、汽车核心芯片等对于海外厂商的依赖度较高,而且电子尤其是半导体行业具有人才、技术、资本密集型特征,虽然国内厂商积极推动国产化进程,但由于技术沉淀、人才储备、量产经验等问题,存在国产化进程不及预期风险。
04 Sandisk宣布涨价10%,华为发布会推出麒麟9020芯片
半导体:Sandisk宣布将产品价格上调10%以上。美对华芯片制造设备出口全面收紧。
当地时间9月4日,Sandisk宣布将面向所有渠道和消费者客户的产品价格上调10%以上。Sandisk表示正看到对闪存产品的强劲需求,这是受人工智能应用以及数据中心、客户端和移动领域日益增长的存储需求的推动,基于此,Sandisk决定对所有渠道和消费者客户的产品价格调涨10%以上。为了确保能提供高性能闪存解决方案并支持持续的创新投资,Sandisk目前正在对闪存产品组合进行价格调整。Sandisk表示,即日起,这些调整仅适用于新的报价和订单,不适用于现有的承诺。未来将继续定期进行价格评估,并可能在未来几个季度进行其他调整。
8月29日,美国商务部宣布将英特尔半导体(大连)有限公司、三星中国半导体有限公司以及SK海力士半导体(中国)有限公司移出“经验证最终用户”授权名单,该措施将于公告发布之日起120天后生效。豁免取消后,所有含美国技术(含软件、零部件、整机)的芯片制造设备向中国工厂发货,必须逐案申请出口许可证。美国商务部工业安全局仅计划允许三星、SK海力士采购维持中国现有厂房运作的美国设备与技术,用来扩产或升级中国厂房的设备执照申请不会获得许可。三星电子40%的NAND闪存在其西安工厂生产,而SK海力士40%的DRAM和20%的NAND闪存在其无锡工厂和大连工厂生产。
风险提示:未来中美贸易摩擦可能进一步加剧,存在美国政府将继续加征关税、设置进口限制条件或其他贸易壁垒风险;宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险;全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。
05AI新纪元:砥砺开疆・智火燎原
算力涉及从芯片到数据中心的全产业链条
算力产业链涉及到诸多环节。如先进制程制造、以Chiplet为代表的2.5D/3D封装、HBM、AI芯片、板卡组装、交换机、光模块、液冷、AI服务器、IDC出租运维。

先进制程制造是算力的基石。制程越先进,意味着晶体管密度越高,单个芯片能提供的算力就越强,能效也越高。AI芯片的性能直接取决于所采用的半导体制造工艺,为了在有限的芯片面积上集成更多的计算单元并控制功耗,业界正不断追求更先进的制程节点。目前,7nm及以下的先进制程已成为高端AI芯片的标配。台积电的5nm、3nm,以及英特尔的Intel 4、18A等先进节点,都是这场算力竞赛的战略制高点。
Chiplet与2.5D/3D封装助力突破单片芯片的物理极限。随着摩尔定律放缓,单纯依靠缩小晶体管尺寸来提升性能变得愈发困难。Chiplet(芯粒)技术应运而生,它将一个大型芯片的功能分解成多个独立的、可灵活组合的“小芯片”,然后通过先进的封装技术将它们集成在一起。这种“化整为零,再聚零为整”的模式,带来了多重优势:可以混合搭配不同制程的芯粒,优化成本与性能;提高了良率;并且能够突破单片芯片的尺寸限制,实现性能的横向扩展。为了将这些芯粒高速互联,2.5D/3D封装技术至关重要。2.5D封装(如台积电的CoWoS)通过一个硅中介层(Interposer)连接各个芯粒,而3D封装则直接将芯粒垂直堆叠,进一步缩短了数据传输距离,提供了更高的带宽和更低的延迟。
HBM为AI芯片输送“数据弹药”。AI计算是典型的数据密集型任务,需要在计算核心和内存之间频繁交换。如果内存带宽不足,即使AI芯片的计算能力再强,也会因为数据供应不上而达不到较高的利用率。HBM正是为解决这一瓶颈而设计。HBM通过3D堆叠技术,将多个DRAM芯片垂直整合,并与AI芯片一同封装在基板上,实现了极高的数据传输带宽和更低的功耗。从HBM2E到HBM3,再到最新的HBM3E,其带宽和容量不断翻倍。
AI芯片是算力产业中的核心。AI芯片是整个算力产业链的核心,目前市场由英伟达的GPU主导,其CUDA生态系统构筑了强大的护城河。除了GPU,还涌现出众多针对AI特定任务进行优化的ASIC和FPGA等。
板卡组装是从芯片到产品的关键一环。设计精良的AI芯片需要被集成到板卡上才能发挥作用。这个环节主要由ODM厂商,如富士康、纬创等巨头主导。它们负责将AI芯片、HBM、供电模块、散热器等数百个元器件精密地组装在一块PCB上,这一过程对制造工艺和质量控制有着较高的要求。
交换机与光模块对于构建大型计算网络至关重要。单个AI服务器的算力有限,训练大模型需要将成千上万台服务器连接成一个庞大的计算集群。在这个集群中,高速交换机和光模块扮演着“神经网络”的角色,负责在服务器之间高速传输数据。随着AI集群规模的扩大,对网络带宽和延迟的要求也水涨船高,推动着交换机端口速率从400G向800G,甚至1.6T演进,光模块需求也随之激增。
AI服务器的功率密度极高,一张高端AI加速卡的功耗就可达1200瓦甚至更高。传统的风冷散热方式已捉襟见肘,液冷技术因此成为必然选择。直接到芯片的液冷通过在发热量最大的芯片上安装冷板,利用液体循环带走热量。液冷不仅散热效率远高于风冷,还能显著降低数据中心的能耗(PUE),节省空间,随着新一代AI芯片的功耗快速提升,液冷正迅速成为新建AI数据中心的主流散热方案。
所有上述部件最终汇聚成AI服务器。这些服务器由戴尔、超微电脑等品牌厂商或广达、纬颖等ODM厂商制造,它们针对AI工作负载进行深度优化,能够容纳多个AI加速器并提供强大的数据处理能力。这些AI服务器被部署在IDC中,由专业的IDC服务商或云服务巨头进行出租和运维。它们提供稳定可靠的电力、制冷、网络和物理安全保障,将算力以MaaS、SaaS、PaaS、IaaS形式交付给大模型的开发者和使用者。
人工智能芯片发展趋势及展望
从广义上讲,能运行AI算法的芯片都叫AI芯片。CPU、GPU、FPGA、NPU、ASIC都能执行AI算法,但在执行效率层面上有巨大的差异。CPU可以快速执行复杂的数学计算,但同时执行多项任务时,其性能开始下降,目前行业内基本公认CPU不适用于AI计算。
CPU+XPU的异构方案成为大算力场景标配,GPU为应用最广泛的AI芯片。目前业内广泛认同的AI芯片类型包括GPU、FPGA、NPU等。由于CPU负责对计算机的硬件资源进行控制调配,也要负责操作系统的运行,在现代计算系统中仍不可或缺。GPU、FPGA等芯片都是作为CPU的加速器而存在,因此目前主流的AI计算系统均为CPU+XPU的异构并行。CPU+GPU是目前最流行的异构计算系统,在HPC、图形图像处理以及AI训练/推理等场景为主流选择。根据中国信通院《先进计算蓝皮书》,2024年,搭载GPU的AI服务器占比约为71%,其中英伟达的市场占有率接近90%,AMD约为8%;随着全球领先的云服务商不断加大对自研芯片的应用力度,非GPU的AI芯片市场规模显著增长,其中ASIC芯片在AI服务器中的占比已攀升至26%。

GPU性能、功能经历长期迭代升级,成为AI芯片中应用最广泛的选择
GPU能够进行并行计算,设计初衷是加速图形渲染。NVIDIA在1999年发布GeForce 256图形处理芯片时首先提出GPU(Graphics Processing Unit)的概念,并将其定义为“具有集成转换、照明、三角形设置/裁剪和渲染引擎的单芯片处理器,每秒能够处理至少1000万个多边形”。从计算资源占比角度看,CPU包含大量的控制单元和缓存单元,实际运算单元占比较小。GPU则使用大量的运算单元,少量的控制单元和缓存单元。GPU的架构使其能够进行规模化并行计算,尤其适合逻辑简单,运算量大的任务。GPU通过从CPU承担一些计算密集型功能(例如渲染)来提高计算机性能,加快应用程序的处理速度,这也是GPU早期的功能定位。

CUDA将GPU的计算能力扩展至图形处理之外,成为更通用的计算设备。在GPU问世以后,NVIDIA及其竞争对手ATI(被AMD收购)一直在为他们的显卡包装更多的功能。2006年NVIDIA发布了CUDA开发环境,这是最早被广泛应用的GPU计算编程模型。CUDA将GPU的能力向科学计算等领域开放,标志着GPU成为一种更通用的计算设备GPGPU(General Purpose GPU)。NVIDIA也在之后推出了面向数据中心的GPU产品线。

GPU性能提升与功能丰富逐步满足AI运算需要。2010年NVIDIA提出的Fermi架构是首个完整的GPU计算架构,其中提出的许多新概念沿用至今。Kepler架构在硬件上拥有了双精度计算单元(FP64),并提出GPU Direct技术,绕过CPU/System Memory,与其他GPU直接进行数据交互。Pascal架构应用了第一代NVLink。Volta架构开始应用Tensor Core(张量核心),对AI计算加速具有重要意义。回顾NVIDIA GPU硬件变革历程,工艺、计算核心数增加等基础特性的升级持续推动性能提升,同时每一代架构所包含的功能特性也在不断丰富,逐渐更好地适配AI运算的需要。

AI的数据来源广泛,GPU逐渐实现对各类数据类型的支持。AI应用处理的数据包括文字、图片或视频,数据精度类型差异大。对于数据表征来讲,精度越高,准确性越高;但降低精度可以节省运算时间,减少成本。近年来,AI推理正加速向低精度演进,尤其在大模型部署环节,为压缩模型规模、提升吞吐量,INT8和FP8等低精度类型被广泛采用。其中,FP8由NVIDIA Hopper架构引入,兼顾表示范围与动态精度,适用于大模型训练与推理阶段;而FP4则首次由NVIDIA Blackwell架构支持,进一步降低数据位宽至4位,用于推理过程中极致压缩模型与加速执行,代表AI计算精度向更低维度延伸的方向。整体来看,未来AI硬件的发展趋势将是,训练阶段采用如FP8等具备精度与动态范围平衡的新型低精度格式,在推理阶段则尝试FP4等极限精度形式,并结合精度混合自适应精度切换等机制,在保证模型准确率的前提下最大化能效比。


均衡分配资源的前提下,处理低精度的硬件单元数量更多,意味着更高的算力性能。GPU作为加速器得到广泛应用一定程度上得益于它的通用性,为了在不同精度的数据类型上具有良好的性能,以兼顾AI、科学计算等不同场景的需要,英伟达在分配处理不同数据类型的硬件单元时大体上保持均衡。因为低精度数据类型的计算占用更少的硬件资源,同一款GPU中的处理低精度数据类型的硬件单元的数量较多,对应计算能力也较强。以V100为例,每个SM中FP32单元的数量都为FP64单元的两倍,最终V100的FP32算力(15.7 TFLOPS)也近似为FP64(7.8 TFLOPS)的两倍,类似的规律也可以在各代架构旗舰A100、H100和B200中看到。

GPU引入特殊硬件单元加速AI的核心运算环节。矩阵-矩阵乘法(GEMM)运算是神经网络训练和推理的核心,本质是在网络互连层中将大矩阵输入数据和权重相乘。矩阵乘积的求解过程需要大量的乘积累加操作,而FMA(Fused Multiply–Accumulate operation,融合乘加)可以消耗更少的时钟周期来完成这一过程。传统CUDA Core执行FMA指令,硬件层面需要将数据按寄存器->ALU->寄存器->ALU->寄存器的方式来回搬运。2017年发布的Volta架构首度引入了Tensor Core(张量核心),即NVIDIA研发的新型处理核心。根据NVIDIA数据,Volta Tensor Core可以在一个GPU时钟周期内执行4×4×4=64次FMA操作,吞吐量是Pascal架构下CUDA Core的12倍。

Tensor Core持续迭代提升其加速能力。Volta架构引入Tensor Core的改动使GPU的AI算力有了明显提升,后续在每一代的架构升级中,Tensor Core都有比较大的改进,核心的大小和数量都在增加,支持的数据类型也逐渐增多。Blackwell架构的Tensor Core已迭代至5.0,支持新的数据类型FP4,Blackwell FP4 Tensor Core的吞吐量是Ada FP8 Tensor Core的2倍。

Tensor Core加速下,低精度比特位宽的算力爆发式增长,契合AI计算需要。Tensor Core的应用使算力快速、高效增长,通过选取Pascal至Hopper架构时期每一代的旗舰数据中心显卡,对比经Tensor Core加速前后的FP16算力指标可以得到:(1)经Tensor Core加速的FP16算力明显高于加速之前。(2)每单位Tensor core支持的算力明显高于每单位Cuda Core支持的算力。同时,Tensor Core从2017年推出以来首先完善了对低精度数据类型的支持,顺应了AI发展的需要。

数据访问支配着计算能力利用率。AI运算涉及到大量数据的存储与处理,根据Cadence数据,与一般工作负载相比,每台AI训练服务器需要6倍的内存容量。而在过去几十年中,处理器的运行速度随着摩尔定律高速提升,而DRAM的性能提升速度远远慢于处理器速度。目前DRAM的性能已成为整体计算机性能的一个重要瓶颈,即所谓阻碍性能提升的“内存墙”。除了性能之外,内存对于能效比的限制也成为一个瓶颈,Cadence数据显示,在自然语言类AI负载中,存储消耗的能量占比达到82%。

GPU采用高带宽HBM以降低“内存墙”影响。为防止占用系统内存并提供较高的带宽和较低的延时,GPU均配备有独立的内存。常规的GDDR焊接在GPU芯片周边的PCB板上,与处理器之间的数据传输速率慢,并且存储容量小,成为运算速度提升的瓶颈。HBM裸片通过TSV进行堆叠,然后HBM整体与GPU核心通过中介层互连,因此HBM获得了极高的带宽,并节省了PCB面积。目前,GDDR显存仍是消费级GPU的行业标准,HBM则成为数据中心GPU的主流选择。

硬件单元的改进与显存升级增强了单张GPU算力的释放。然而,随着Transformer模型的大规模发展和应用,模型参数量呈爆炸式增长,GPT-3参数量达到了1750亿,相比GPT增长了近1500倍,预训练数据量更是从5GB提升到了45TB。大模型参数量的指数级增长带来的诸多问题使GPU集群化运算成为必须:
(1)即使最先进的GPU,也不再可能将模型参数拟合到主内存中。
(2)即使模型可以安装在单个GPU中(例如,通过在主机和设备内存之间交换参数),所需的大量计算操作也可能导致在没有并行化的情况下不切实际地延长训练时间。根据NVIDIA数据,在8个V100 GPU上训练一个具有1750亿个参数的GPT-3模型需要36年,而在512个V100 GPU上训练需要7个月。

NVIDIA开发NVLink技术解决GPU集群通信。在硬件端,GPU之间稳定、高速的通信是实现集群运算所必须的条件。传统x86服务器的互连通道PCIe的互连带宽由其代际与结构决定,例如x16 PCIe 4.0双向带宽仅为64GB/s。除此之外,GPU之间通过PCIe交互还会与总线上的CPU操作竞争,甚至进一步占用可用带宽。NVIDIA为突破PCIe互连的带宽限制,在P100上搭载了首项高速GPU互连技术NVLink(一种总线及通讯协议),GPU之间无需再通过PCIe进行交互。

NVLink继续与NVIDIA GPU架构同步发展,每一种新架构都伴随着新一代NVLink。第五代NVLink为每个GPU提供1.8 TB/s的双向带宽,是上一代的2倍,约为第一代NVLink的11倍。

NVIDIA开发基于NVLink的芯片NVSwitch,作为GPU集群数据通信的“枢纽”。NVLink 1.0技术使用时,一台服务器中的8个GPU无法全部实现直接互连。同时,当GPU数量增加时,仅依靠NVLink技术,需要众多数量的总线。为解决上述问题,NVIDIA在NVLink 2.0时期发布了NVSwitch,实现了NVLink的全连接。NVSwitch是一款GPU桥接芯片,可提供所需的NVLink交叉网络,在GPU之间的通信中发挥“枢纽”作用。借助于NVswitch,每颗GPU都能以相同的延迟和速度访问其它的GPU。

通过添加更多NVSwitch来支持更多GPU,集群分布式运算得以实现。当训练大型语言模型时,NVLink网络也可以提供显著的提升。NVSwitch已成为高性能计算(HPC)和AI训练应用中不可或缺的一部分。

NVIDIA最新AI芯片Rubin各项指标全面升级,将于2026年上市。NVIDIA下一代平台Rubin于2024年6月Computex大会上亮相,该平台具有新的GPU架构、新的ARM架构CPU Vera、新的HBM4存储颗粒、覆盖12颗HBM4的更大尺寸CoWoS封装,以及NVLink6、CX9 SuperNIC网卡和新一代融合IB网络与以太网的新型交换机X1600。

ASIC通过特殊架构设计对AI运算起到加速作用
NPU存算一体,带来了更高的人工智能算法运行效率。ASIC为了适应某个特定领域中的常见的应用和算法而设计,NPU(神经网络处理器)属于其中一种,常被设计用于神经网络运算的加速。NPU的核心是人工神经网络,即一套由若干人工神经元结点通过突触两两连接、模仿生物神经网络构建而成的算法总和;在人工神经网络中,突触负责记录神经元间联结的强弱(即权重)、神经元则可以近似为一个输入值由与其相连的神经元的输出值和突触权重共同决定的激励函数。通过调整网络拓扑结构、突触权重和神经元阈值,可以实现对特定知识的表达,该过程即为神经网络的“学习”过程。

较传统冯·诺依曼结构下的CPU/GPU,NPU具备“存算一体”优势。在传统的冯·诺依曼结构下,数据存储和数据计算分别独立由存储器和计算器来完成,分离式结构制约了数据交换效率,而在人工神经网络中,数据存储和计算都由调整突触的权重来呈现。神经网络训练完毕后,激励函数和权重暂时固化,直到下一次调用时可以直接计算出当前输入对应的输出结果。人工神经网络发展至今,NPU采用过MLP、CNN、RNN、GNN、Transformer、Autoencoder等多种典型结构。

目前已量产的NPU或搭载NPU模块的ASIC众多,知名的芯片包括谷歌TPU(Tensor Processing Unit)、华为昇腾、特斯拉FSD、特斯拉Dojo等。各家厂商在计算核心的设计上有其差异,例如谷歌TPU的脉动阵列,华为昇腾的达芬奇架构。
以谷歌TPU及计算核心结构脉动阵列为例,对比其相较于CPU、GPU的区别:
CPU和GPU均具有通用性,但以频繁的内存访问导致资源消耗为代价。CPU和GPU都是通用处理器,可以支持数百万种不同的应用程序和软件。对于ALU中的每一次计算,CPU、GPU都需要访问寄存器或缓存来读取和存储中间计算结果。由于数据存取的速度往往大大低于数据处理的速度,频繁的内存访问,限制了总吞吐量并消耗大量能源。
谷歌TPU并非通用处理器,而是将其设计为专门用于神经网络工作负载的矩阵处理器。TPU不能运行文字处理器、控制火箭引擎、执行银行交易,但它们可以处理神经网络的大量乘法和加法,速度极快,同时消耗更少的能量,占用更小的物理空间。TPU内部设计了由乘法器和加法器构成的脉动阵列。在计算时,TPU将内存中的参数加载到乘法器和加法器矩阵中,每次乘法执行时,结果将传递给下一个乘法器,同时进行求和。所以输出将是数据和参数之间所有乘法结果的总和。在整个海量计算和数据传递过程中,完全不需要访问内存。这就是为什么TPU可以在神经网络计算上以低得多的功耗和更小的占用空间实现高计算吞吐量。

脉动阵列本质上是在硬件层面多次重用输入数据,在消耗较小的内存带宽的情况下实现较高的运算吞吐率。脉动阵列结构简单,实现成本低,但它灵活性较差,只适合特定运算。然而,AI神经网络需要大量卷积运算,卷积运算又通过矩阵乘加实现,正是脉动阵列所适合的特定运算类型。脉动阵列理论最早在1982年提出,自谷歌2017年首次将其应用于AI芯片TPU中,这项沉寂多年的技术重回大众视野,多家公司也加入了脉动阵列行列,在自家加速硬件中集成了脉动阵列单元。

AI服务器需求推动芯片自研节奏加快。AI服务器需求正带动北美四大CSP加速自研ASIC芯片,平均1-2年就会推出升级版本,以降低对英伟达、AMD GPU的依赖,并控制成本,改善营运成本支出。
谷歌自研的TPU芯片作为其AI加速基础设施的核心,十年时间内持续迭代演进至第7代。谷歌TPU自2015年推出以来,广泛部署于谷歌数据中心,用于支持搜索引擎、语音识别、图像识别、推荐系统等核心业务。谷歌通过TPU Pod实现数千颗TPU的集群化互联,形成AI超级计算平台,支撑包括PaLM、Gemini等在内的大模型训练,成为其AI基础设施的重要一环。在Google Cloud Next 25大会上,谷歌推出了第7代TPU v7p,其每瓦性能是第六代TPU v6e的两倍,单颗芯片的HBM容量是第6代的6倍,芯片间互连双向带宽提升至第6代的1.5倍,可以扩展至高达9216颗芯片。

AWS围绕推理与训练两大核心场景,分别推出了Inferentia和Trainium两大系列。AWS自2018年起布局自研芯片,推出推理专用芯片Inferentia,以及用于大规模训练的Trainium,广泛部署于Amazon EC2实例中,支撑从语音识别、机器翻译到生成式AI的多种场景应用。结合Amazon Neuron SDK软件栈,AWS芯片实现对PyTorch、TensorFlow等主流框架的兼容,支持大模型推理与训练的高效部署,成为AWS云服务AI算力体系的重要组成部分。2024年底AWS发布了第三代AI训练芯片Trainium3。这款芯片是AWS首款采用3nm工艺制造的AI芯片,相较前代产品,性能提升高达2倍,能效提升40%。Trainium3支持高达144GB的HBM3e,搭载Trainium3的UltraServer性能预计是Trn2 UltraServer的4倍,预计将于2025年底上线。

Meta自研AI加速芯片为推荐算法和推理任务设计。Meta自研的AI加速芯片MTIA(Meta Training and Inference Accelerator)是其构建高效AI基础设施的关键组成部分,专为大规模推荐系统和推理任务设计,旨在降低对通用GPU的依赖,提升能效比和系统可控性。截至2024年,Meta已推出第二代MTIA芯片,并在全球16个数据中心部署,广泛应用于Facebook、Instagram等平台的广告排序和内容推荐模型中。第二代MTIA芯片采用台积电5nm工艺制造,运行频率为1.35GHz,热设计功耗为90W。与前代相比,MTIA v2在密集计算性能上提升了3.5倍,稀疏计算性能提升了7倍,片上内存容量翻倍至256MB,带宽提升至2.7TB/s。

微软自研ASIC支持8bit以下的数据类型。微软于2023年11月发布首款AI芯片Maia 100,采用台积电5nm制程和CoWoS-S封装,并支持8-bit以下的数据类型,即MX数据类型,这一特性能够促进软硬件协同设计,显著加快模型训练和推理的速度,其设计目的是为微软Copilot或Azure OpenAI Service等服务提供支持。据The Information报道,微软原计划于2025年推出的下一代自研AI芯片Maia 200可能延期至2026年。

人工智能芯片制造及封装发展趋势及展望
大算力芯片要求性能持续提升,后摩尔时代急需高性价比解决方案。随着参数增加,AI大模型对于算力需求大幅提升,GPU等大算力芯片的性能提升遭遇两大瓶颈:一方面,进入28nm制程节点后,摩尔定律逐渐失效,先进制程的成本快速提升。根据IBS统计,在达到28nm制程节点以后,如果继续缩小制程节点,每百万门晶体管的制造成本不降反升,摩尔定律开始失效。而且应用先进制程的芯片研发费用大幅增长,5nm制程的芯片研发费用增至5.42亿美元,几乎是28nm芯片研发费用的10.6倍,高额的研发门槛进一步减少了先进制程的应用范围。另一方面,内存带宽增长缓慢,限制处理器性能。在传统PCB封装中,走线密度和信号传输速率难以提升,因而内存带宽缓慢增长,导致来自存储带宽的开发速度远远低于处理器逻辑电路的速度,带来“内存墙”的问题。

Chiplet设计+异构先进封装提供了性能与成本平衡的最佳方案。Chiplet即“小芯片”,是指预先制造好、具有特定功能、可组合集成的晶片(Die)。Chiplet技术背景下,可以将大型单片芯片划分为多个相同或者不同的小芯片,这些小芯片可以使用相同或者不同的工艺节点制造,再通过跨芯片互连和先进封装技术进行封装级集成,主要优势包括:1)可以突破光罩尺寸对单芯片面积的限制;2)可以充分发挥旧工艺节点的性价比优势,有效提升产品的良率,降低成本;3)通过集成不同工艺的芯粒,可以形成更加灵活的产品策略;4)先进封装的走线密度高,信号传输速率有很大的提升空间,同时能大大提高互连密度,成为解决内存墙问题的主要方法之一。

为实现异构集成的Chiplet封装,需要借助到2D/2.1D/2.3D/2.5D/3D等一系列先进封装工艺。先进封装的不同层次主要依据多颗芯片堆叠的物理结构和电气连接方式划分,例如2D封装中的芯片直接连接到基板,其他封装则以不同形式的中介层完成互联。其中,2.5D封装常用于计算核心与HBM的封装互连,3D封装常用于HBM显存的多层堆叠,并有望用于不同IC的异构集成。

先进封装市场快速成长,相对高阶的封装形式将呈现更快增速。根据Yole数据,2022年全球封装市场中,先进封装占比已达到47%。预计到2028年,先进封装市场占比将增至58%,规模约为786亿美元,2022年-2028年CAGR约为10.0%,明显高于传统封装市场的2.1%和市场整体的6.2%。

CoWoS:2.5D封装重要解决方案,实现计算核心与HBM封装互连。计算核心与HBM通过2.5D封装互连,台积电开发的CoWoS封装技术为广泛使用的解决方案。台积电早在2011年推出CoWoS技术,并在2012年首先应用于Xilinx的FPGA上。此后,华为海思、英伟达、谷歌等厂商的芯片均采用了CoWoS,例如GP100(P100显卡核心),TPU 2.0。如今CoWoS已成为HPC和AI计算领域广泛应用的2.5D封装技术,绝大多数使用HBM的高性能芯片,包括大部分创企的AI训练芯片都应用了CoWoS技术。



CoWoS帮助台积电取得英伟达、AMD等高性能计算芯片订单。英伟达A100、H100等高端GPU,均采用台积电CoWoS-S封装,分别配备80GB HBM2E、80GB HBM3。全新的Blackwell架构GPU B200则采用了CoWoS-L封装,配备192GB HBM3E,带宽高达8TB/s。根据DIGITIMES报道,AMD MI200原本由日月光集团与旗下矽品提供FO-EB先进封装(扇出嵌入式桥接),而新的MI系列数据中心芯片重新采用台积电先进封装CoWoS。2025年发布的MI350系列GPU基于CoWoS-S,实现了288GB HBM3E,8TB/s内存带宽的超高性能配置。
CoPoS化圆为方,是CoWoS先进封装技术新变革。为了满足更多空间的需求,台积电公布了CoPoS(Chips on Panel on Substrate)技术。CoPoS技术将从圆形晶圆转化为矩形面板,CoPoS可提供5倍以上的可用面积,使得单个封装中集成更多的HBM、多颗I/O芯片和计算芯片成为可能。台积电将于2026年建立一条CoPoS试验线,量产预计将于2028年底至2029年初在先进封装工厂AP7进行。

台积电SoIC是3D异构集成的技术平台,采用wafer-on-wafer键合技术。SoIC技术采用TSV技术,可以实现非凸点键合结构,将许多不同性质的相邻芯片集成在一起。SoIC技术将同构和异构小芯片集成到单个类似SoC的芯片中,该芯片具有更小的占用空间和更薄的外形,可以整体集成到CoWoS和InFO中。从外观上看,新集成的芯片就像一个普通的SoC芯片,但嵌入了所需的异构集成功能。
SoIC主要分为SoIC_CoW(Chip on Wafer)和SoIC_WoW(Wafer on Wafer)。1)SoIC_CoW技术将不同尺寸、功能、节点的晶粒进行异质整合。2)SoIC_WoW技术通过晶圆堆叠工艺实现异构和同质3D硅集成。紧密的键合间距和薄的TSV可实现最小的寄生以实现更好的性能、更低的功耗和延迟以及更小的外形尺寸。WoW适用于高良率节点和相同裸片尺寸的应用或设计,甚至支持与第3方晶圆的集成。台积电在CoW方面正在开发N7-on-N7和N5-on-N5等;WoW方面,台积电则在开发Logic-on-DTC(Deep Trench Capacitor)。

基于微凸块的3D封装借助微凸点连接芯片,在连接密度、性能等方面受限。传统3D封装在后端工艺中借助微凸点(Bump)连接堆叠的芯片,但微凸点的尺寸很难缩小到10μm以下,限制了堆叠芯片的I/O引脚数量。此外,按比例排列的微凸点增加了寄生电容、电阻和电感,降低了其性能和功率。
台积电SoIC 3D封装技术使芯片连接紧密,并在互联带宽和散热上表现优异。台积电SoIC的键合技术在前端工艺完成,接合间距更小,使芯片更紧密地连接在一起,提供超过10K/mm2的垂直互连密度,用于实现超高带宽互连。在热性能方面,台积电SoIC键合的热阻比微凸点下降低35%。

台积电公布了其SoIC研发进度,CoW和WoW的研发进度基本一致,为N7/N6工艺,已于2023年实现基于N5工艺,并预计将于2035年前实现1μm以内的SoIC互连。3D IC未来有望迎来快速发展和商用化进程。

HBM及存储芯片发展趋势及展望
HBM采用3D封装,通过TSV将多个DRAM Die垂直堆叠。在后摩尔时代,存储带宽制约了计算系统的有效带宽,导致芯片算力性能提升受到限制,HBM应运而生,与传统DRAM不同,HBM是3D结构,它使用TSV技术将数个DRAM裸片堆叠起来,形成立方体结构,即DRAM芯片上搭上数千个细微孔并通过垂直贯通的电极连接上下芯片;底层则是DRAM逻辑控制单元,负责整体时序与控制。从技术角度看,HBM促使DRAM从传统2D加速走向立体3D,充分利用空间、缩小面积,契合半导体行业小型化、集成化的发展趋势。HBM和硅互联技术突破了内存容量与带宽瓶颈,被视为新一代DRAM解决方案。而相较传统封装方式,TSV技术能够缩减30%体积,并降低50%能耗。

HBM相对传统内存数据传输线路的数量大幅提升。存储器带宽指单位时间内可以传输的数据量,要想增加带宽,最简单的方法是增加数据传输线路的数量。在典型的DRAM中,每个芯片有八个DQ引脚,也就是数据输入/输出引脚。在组成DIMM模块单元之后,共有64个DQ引脚。然而,随着系统对DRAM和处理速度等方面的要求有所提高,数据传输量也在增加。因此,DQ引脚的数量(D站的出入口数量)已无法保证数据能够顺利通过。HBM由于采用了系统级封装(SIP)和硅通孔(TSV)技术,拥有高达1024个DQ引脚,但其外形尺寸(指物理面积)却比标准DRAM小10倍以上。由于传统DRAM需要大量空间与CPU和GPU等处理器通信,而且它们需要通过引线键合或PCB迹线进行连接,因此DRAM不可能对海量数据进行并行处理。相比之下,HBM产品可以在极短距离内进行通信,增加了DQ路径,显著加快了信号在堆叠DRAM之间的传输速度,实现了低功耗、高速的数据传输。

目前HBM产品带宽增加了七倍,已接近1TB/秒的里程碑节点。显存带宽=显存等效频率×显存位宽/8,因此频率和带宽决定显存性能。HBM显存可以提供1024bit起跳的显存位宽,4颗粒堆叠式的显存可达到128GB/s的带宽。HBM能大幅提高数据处理速度,每瓦带宽比GDDR5高出3倍多,且HBM2比GDDR5节省了94%的表面积,减少20%+的功耗。2021年,SK海力士和Rambus先后发布最高数据传输速率6.4Gbps和8.4Gbps的HBM3产品,每个堆栈将提供超过819GB/s和1075GB/s的传输速率,支持16-Hi堆栈,堆栈容量达到24GB。HBM3带宽达819GB/s,相对初代增加了7倍,是LPDDR5的近100倍,较DDR5、GDDR6高出10倍以上。与传统内存相比,HBM的存储密度更大、功耗更低、带宽更高,多用于与数据中心GPGPU配合工作,可以取代传统的GDDR,HBM优势在于高位宽,但是频率相对偏低。

HBM正在成为AI服务器GPU的标配。AI服务器需要在短时间内处理大量数据,对带宽提出了更高的要求,HBM成为了重要的解决方案。AI服务器GPU市场以NVIDIA H100、A100、A800以及AMD MI250、MI250X系列为主,基本都配备了HBM。HBM方案目前已演进为较为主流的高性能计算领域扩展高带宽的方案。以英伟达为例,2022-2023年英伟达GPU搭载的HBM主要是HBM2/2E,2023年则逐步开始搭载HBM3,2024年则主要是HBM3和HBM3E;当前,英伟达最新一代的GB200,Blackwell GPU搭载的是8层堆叠单颗16GB的HBM3E,2025年下半年量产的GB300,Blackwell GPU搭载的是12层堆叠单颗24GB的HBM3E,并且Rubin系列将搭载HBM4/4e,配置规格不断提升。

SK海力士是HBM开发的先行者,并在技术开发和市场份额上占据领先地位。2014年,SK海力士与AMD联合开发了全球首款HBM产品。SK海力士的HBM3发布7个月后实现了量产,将搭载于NVIDIA H100之上。根据BussinessKorea的报道,SK海力士在HBM市场已获得60%-70%的市场份额。SK海力士之后,三星、美光推出了各自的HBM产品,迭代至HBM3e-12Hi。晶圆代工厂商包括如台积电、格芯等也在发力HBM相关的封装技术。
随着HBM的性能提升,未来市场空间广阔。以位元计算,目前HBM占整个DRAM市场比重仅约1.5%,渗透率提升空间较大。在将GPU等AI芯片推向高峰的同时,也极大带动了市场对新一代内存芯片HBM(高带宽内存)的需求,据悉,2023年开年以来,三星、SK海力士的HBM订单就快速增加,价格也水涨船高。2023年HBM市场规模为40亿美元,预计2024年增长至150亿美元,2026年增长至350亿美元。
HBM快速迭代,HBM4即将进入量产。结构上,2025年HBM3E将占据主导,根据SK海力士,2024年其HBM3E收入将占HBM收入一半以上,2025年12层HBM3E供给量将超过8层产品,12层HBM4计划于25H2发货。(1)HBM3E:三大原厂相继推出12Hi产品,这些12Hi的HBM预计用在英伟达的B300A(B200A Ultra)和B300上。(2)HBM4:三星、海力士计划24Q4开始HBM4的流片,预计2026年用在英伟达下一代的Rubin芯片上。

3D IC:多芯片垂直堆叠增强互联带宽,未来发展潜力巨大。3D IC是指使用FAB工艺在单个芯片上堆叠多个器件层,包括多Logic芯片间的堆叠。与2.5D封装相比,3D IC封装互连方式有所不同。2.5D封装是通过TSV转换板连接芯片,而3D IC封装是将多个芯片垂直堆叠在一起,并通过直接键合技术实现芯片间的互连。在2.5D结构中,两个或多个有源半导体芯片并排放置在硅中介层上,以实现极高的芯片到芯片互连密度。在3D结构中,有源芯片通过芯片堆叠集成,以实现最短的互连和最小的封装尺寸。另一方面,2.5D封装和3D IC封装的制造工艺也有所不同,2.5D封装需要制造硅基中介层,并且需要进行微影技术等复杂的工艺步骤;而3D IC封装需要进行直接键合技术等高难度的制造工艺步骤。当前3D IC封装主流产品包括台积电SoIC技术、英特尔Foveros技术和三星X-Cube技术。

国产人工智能芯片发展趋势及展望
海外龙头占据垄断地位,AI加速芯片市场呈现“一超多强”态势。数据中心CPU市场上,英特尔份额有所下降但仍保持较大领先优势,AMD持续抢占份额势头正盛。AI加速计算芯片市场上,英伟达凭借硬件优势和软件生态一家独大,在训练、推理端均占据领先地位。根据IDC数据,2024年国内AI加速计算芯片市场中,英伟达出货份额达70%,华为昇腾出货份额23%,其余厂商合计占比7%。国内厂商起步较晚,正逐步发力,部分加速芯片领域已经涌现出一批破局企业,虽然在高端AI加速计算芯片领域与海外厂商存在较大差距,但在国内市场上已经开始取得部分份额,根据IDC数据,2024年国内AI芯片市场中,华为昇腾出货64万片,出货2.6万片,燧原出货1.3万片。未来,随着美国持续加大对中国高端芯片的出口限制,AI芯片国产化进程有望继续加快。

GPU市场方面,海外龙头占据垄断地位,国产厂商加速追赶。当前英伟达、AMD、英特尔三巨头占据全球GPU芯片市场的主导地位。集成GPU芯片一般在台式机和笔记本电脑中使用,性能和功耗较低,主要厂商包括英特尔和AMD。独立显卡常用于服务器中,性能更高、功耗更大,主要厂商包括英伟达和AMD。分应用场景来看,应用在人工智能、科学计算、视频编解码等场景的服务器GPU市场中,英伟达和AMD占据主要份额。根据JPR预测,2025年Q1英伟达的独立显卡(包括AIB 合作伙伴显卡)的市场份额达92%, AMD和英特尔则分别占比8%、0%。

图形渲染GPU:英伟达引领行业数十年,持续技术迭代和生态构建实现长期领先。2006年起,英伟达GPU架构保持约每两年更新一次的节奏,各代际产品性能提升显著,生态构建完整,GeForce系列产品市占率长期保持市场首位,最新代际GeForce RTX 40系列代表了目前显卡的性能巅峰,采用全新的Ada Lovelace架构,台积电5nm级别工艺,拥有760亿晶体管和18000个CUDA核心,与Ampere相比架构核心数量增加约70%,能耗比提升近两倍,可驱动DLSS 3.0技术。性能远超上代产品。AMD独立GPU在RDNA架构迭代路径清晰,RDNA 3架构采用5nm工艺和Chiplet设计,比RDNA 2架构有54%每瓦性能提升。目前国内厂商在图形渲染GPU方面与国外龙头厂商差距不断缩小。芯动科技的“风华2号”GPU像素填充率48GPixel/s,FP32单精度浮点性能1.5TFLOPS,AI运算(INT8)性能12.5TOPS,实测功耗4~15W,支持OpenGL4.3、DX11、Vulkan等API,实现国产图形渲染GPU突破。在工艺制程、核心频率、浮点性能等方面虽落后于英伟达同代产品,但差距正逐渐缩小。2023年顺利发布JM9系列图形处理芯片,支持OpenGL 4.0、HDMI 2.0等接口,以及H.265/4K 60-fps视频解码,核心频率至少为1.5GHz,配备8GB显存,浮点性能约1.5TFlops,与英伟达GeForce GTX1050性能相近,有望对标GeForce GTX1080。

GPGPU:英伟达和AMD是目前全球GPGPU的领军企业。英伟达的通用计算芯片具备优秀的硬件设计,通过CUDA架构等全栈式软件布局,实现了GPU并行计算的通用化,深度挖掘芯片硬件的性能极限,在各类下游应用领域中,均推出了高性能的软硬件组合,逐步成为全球AI芯片领域的主导者。AMD于2018年发布用于数据中心的Radeon Instinct GPU加速芯片,Instinct系列基于CDNA架构,如MI250X采用CDNA2架构,在通用计算领域实现计算能力和互联能力的显著提升,此外还推出了对标英伟达CUDA生态的AMD ROCm开源软件开发平台。
国内GPGPU厂商正逐步缩小与英伟达、AMD的差距。英伟达凭借其硬件产品性能的先进性和生态构建的完善性处于市场领导地位,国内厂商虽然在硬件产品性能和产业链生态架构方面与前者有所差距,但正在逐步完善产品布局和生态构建,不断缩小与行业龙头厂商的差距。
ASIC市场方面,由于其一定的定制化属性,市场格局较为分散。在人工智能领域,ASIC也占据一席之地。其中谷歌处于相对前沿的技术地位,自2016年以来,就推出了专为机器学习定制的ASIC,即张量处理器(Tensor Processing Unit,TPU)。2025年谷歌推出了第七代张量处理单元(TPU)Ironwood,可扩展至9216个液冷芯片,并通过突破性的芯片间互联,功率接近10兆瓦。据nextplatform介绍,TPU v7p芯片是谷歌首款在其张量核心和矩阵数学单元中支持FP8计算的TPU。之前的TPU支持INT8格式和推理处理,以及BF16格式和训练处理。Ironwood芯片还配备了第三代SparseCore加速器,该加速器首次亮相于TPU v5p,并在去年的Trillium芯片中得到了增强。
国产厂商快速发展,寒武纪等异军突起。通过产品对比发现,目前寒武纪、海思昇腾、遂原科技等国产厂商正通过技术创新和设计优化,持续提升产品的性能、能效和易用性,推动产品竞争力不断提升,未来国产厂商有望在ASIC领域持续发力,突破国外厂商在AI芯片的垄断格局。
生态体系决定用户体验,是算力芯片厂商最深的护城河。虽然英伟达GPU本身硬件平台的算力卓越,但其强大的CUDA软件生态才是推升其GPU计算生态普及的关键力量。从技术角度来讲,GPU硬件的性能门槛并不高,通过产品迭代可以接近龙头领先水平,但下游客户更在意能不能用、好不好用的生态问题。CUDA推出之前GPU编程需要用机器码深入到显卡内核才能完成任务,而推出之后相当于把复杂的显卡编程包装成为一个简单的接口,造福开发人员,迄今为止已成为最发达、最广泛的生态系统,是目前最适合深度学习、AI训练的GPU架构。英伟达在2007年推出后不断改善更新,衍生出各种工具包、软件环境,构筑了完整的生态,并与众多客户合作构建细分领域加速库与AI训练模型,已经积累300个加速库和400个AI模型。尤其在深度学习成为主流之后,英伟达通过有针对性地优化来实现最佳的效率提升性能,例如支持混合精度训练和推理,在GPU中加入Tensor Core来提升卷积计算能力,以及最新的在H100 GPU中加入Transformer Engine来提升相关模型的性能。这些投入包括了软件和芯片架构上的协同设计,使得英伟达能使用最小的代价来保持性能的领先。而即便是英伟达最大的竞争对手AMD的ROCm平台在用户生态和性能优化上还存在差距。CUDA作为完整的GPU解决方案,提供了硬件的直接访问接口,开发门槛大幅降低,而这套易用且能充分调动芯片架构潜力的软件生态让英伟达在大模型社区拥有巨大的影响力。正因CUDA拥有成熟且性能良好的底层软件架构,几乎所有的深度学习训练和推理框架都把对于英伟达GPU的支持和优化作为必备的目标,帮助英伟达持续处于领先地位。

美国对华供应AI芯片管制强度持续升级,H20被纳入管制范围。2022年,美国BIS实施出口管制,英伟达和AMD的高端GPU产品出口受到限制。为满足合规要求,英伟达随后推出了面向中国市场的H800与A800,互联带宽被下调。2023年,BIS公布的先进计算芯片出口管制新规进一步扩大限制范围,以“性能密度”与“总处理性能(TPP)”成为新的标准,使得A100、A800、H100、H800、L40、L40S等多款产品遭到限制。虽然英伟达又推出了性能大幅下调,符合新规的H20,但H20也在今年4月被美国纳入出口管制。
国产算力芯片迎来国产替代窗口期。考虑到英伟达新品迎来大幅性能升级,并面向中国市场禁售,国产算力芯片发展刻不容缓。当前已经涌现出一大批国产算力芯片厂商,昇腾、寒武纪相继推出自研AI芯片,的DCU也逐渐打出知名度,其他配套环节的国产化进程也正在加速推进。
风险提示:北美经济衰退预期逐步增强,国际地缘变局冲击全球供应链韧性,企业海外拓展承压;芯片结构性短缺可能制约产能释放与交付节奏;行业竞争加剧触发价格战隐忧,中低端产品毛利率可能跌破盈亏平衡点;原材料成本高企叠加汇率宽幅波动持续侵蚀外向型企业利润空间;技术端则面临大模型迭代周期拉长的风险),影响AI产业化进程;汽车智能化渗透率及工业AI质检等场景落地进度不及预期,或将延缓第二增长曲线兑现。
06关注中美关税政策对半导体、消费电子产业链的影响
半导体:中国宣布对原产于美国的所有进口商品加征关税,半导体产业链全球化分工,受影响程度取决于原产地判定标准,国产化趋势加速的长期趋势不变。
本周,特朗普政府的“对等关税”政策落地,美国将对所有进口到美国的商品额外征收10%的基础关税,并对一些美国最大贸易伙伴征收更高的关税,如中国34%,欧盟20%,印度26%,韩国25%,越南46%等。半导体在此次关税征收的豁免名单中,但特朗普承诺未来会加征关税。作为回应,中国宣布自2025年4月10日12时01分起,对原产于美国的所有进口商品,在现行适用关税税率基础上加征34%关税。
半导体是中美角逐的关键领域,亦将受到关税政策波及。美国企业在半导体市场占据较大优势,SIA(美国半导体行业协会)的统计数据显示,2023年总部位于美国的半导体公司占据了全球50.2%的市场份额,占据中国市场53.1%的份额。理论上,中国对美半导体产品加征关税将削弱其价格竞争力,减轻国产厂商所承受的压力,并有助于提升其市场份额。
中国海关数据显示,2024年中国集成电路进口金额达到3857.9亿美元,同比增长10.5%。目前,中国大陆的集成电路进口份额高度集中,中国台湾与韩国位列第一与第二,合计占比约58%。中国台湾的台积电、联电、日月光等企业在晶圆制造、封测等环节处于全球领先,巩固了大陆从台湾地区进口集成电路的份额。韩国则主要依靠存储芯片的拉动。马来西亚排名第三,占比约8.5%,得益于大量企业的封测产能在当地布局。美国排名位于第6,占比仅为3%,进口金额不足1000亿人民币。
综上,美国半导体企业占据中国市场较大市场份额,但中国直接从美国进口的产品较少,主要源于半导体产业链的全球化分工。NVIDIA、高通、AMD为代表的美国Fabless企业主导产品的设计与销售,其产品的晶圆制造大多位于台积电,封测环节则位于中国台湾、马来西亚等地。TI、Intel为代表的IDM企业,尽管其晶圆产能部分位于美国本土,但封装产能仍主要分布于东南亚地区。以TI为例,2024年约90%的晶圆制造,70%的封装来自其自有产能,晶圆厂主要位于美国得克萨斯州和犹他州等地,封装产能则集中在东南亚地区。
因此,若未来仍以成品封装地作为原产地依据,加征关税的实际影响或相对有限。但从长期来看,半导体领域的“去美化”趋势与国产化率提升的方向仍将持续。
风险提示:未来中美贸易摩擦可能进一步加剧,存在美国政府将继续加征关税、设置进口限制条件或其他贸易壁垒风险;宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险;全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。
07 美光发布涨价函,存储价格有望逐步回升
半导体:存储大厂美光发布涨价函,主流存储品类价格见底回温的趋势已经形成。
美光继闪迪、长江存储后,也发布涨价函。函件显示,由于需求出现超预期增长,美光决定提高产品价格以应对市场变化。CFM预计,美光本次涨价幅度在10%-15%。
美光、闪迪、长江存储等厂商陆续调价,释放存储行业周期回暖的信号。TrendForce最新预测已将NAND Flash价格止跌回稳的时间节点由25Q3提前至25Q2。供给端,自2024Q4起,NAND Flash原厂陆续减产,减产效应正逐步显现。需求端,消费电子品牌商顺应国际形势变化而提前生产,带动需求,加之PC、智能手机和数据中心等应用领域已开始重建库存。DRAM方面, 2025Q1下游品牌厂大都提前出货因应国际形势变化,有助供应链中DRAM的库存去化,TrendForce预计25Q2传统DRAM(不含HBM)的价格跌幅将收敛季减0%至5%。
渠道市场的存储现货价格也受到备货热度升温而持续走高,价格上涨的品类正越来越多,包括存储颗粒与模组。CFM表示,原厂仍保持强势控货拉涨态度,Good die价格普遍上扬,使得部分现货产品价格出现较大涨幅,存储现货市场供需关系趋紧加剧。
存储大厂自2024年末启动的产能调控措施已初见成效,主流存储品类价格见底回温的趋势已经形成。后续涨价态势能否持续,仍需要关注终端的需求复苏力度及库存去化进度。历史上每一轮大周期,上行、下行周期大致为2年,但23年至今的存储周期开始呈现周期缩短、波动加剧的特征,未来需重点关注头部厂商产能策略动态,以及终端厂商备货节奏等边际变化。
风险提示:未来中美贸易摩擦可能进一步加剧,存在美国政府将继续加征关税、设置进口限制条件或其他贸易壁垒风险;宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险;全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。
08 GTC 2025发布Blackwell Ultra,并更新Rubin架构细节
半导体:英伟达于GTC 2025上发布Blackwell Ultra,并展示下一代Vera Rubin架构的细节,芯片架构持续进化,算力竞争白热化。
2025年3月17日至21日,英伟达于美国加州圣何塞举办年度开发者大会GTC 2025,CEO黄仁勋发表主题演讲。随着新算力平台的硬件性能持续跃升,英伟达通过将进一步巩固其在AI算力基础设施的领先地位。
基于Blackwell Ultra架构的B300 GPU在GTC 2025上首度发布。B300 GPU配备288GB HBM3e内存,是B200的1.5倍,FP4稠密算力达到15 PFLOPS。Blackwell Ultra NVL72平台预计将于2025年下半年推出,将配备72颗GB300芯片,可提供1.1 EFLOPS的稠密FP4算力用于推理,以及0.36 EFLOPS的FP8算力用于训练,算力达到GB200 NVL72的1.5倍。
Vera Rubin将是下一代平台,包括名为Vera的CPU和名为Rubin的GPU。Vera CPU的性能是Grace CPU的2倍,具有88个定制的Arm核心,176个线程。Rubin GPU的显存将升级至HBM4,所支持的互联带宽技术将升级至NVLink 6。Vera Rubin NVL144将于2026年下半年推出,拥有75 TB,带宽13TB/s的HBM4显存,可提供3.6 EFLOPS的FP4算力用于推理,以及1.2 EFLOPS的FP8算力用于训练,算力达到GB300 NVL72的3.3倍。而更强的Rubin Ultra(单颗芯片中封装4颗计算Die)将于2027年下半年推出,显存升级到HBM4e,所支持的互联带宽技术升级至NVLink 7。Rubin Ultra NVL576则将于2027年下半年推出,拥有365 TB,带宽4.6 PB/s的HBM4e显存,可提供15 EFLOPS的FP4算力用于推理,以及5 EFLOPS的FP8算力用于训练,算力达到GB300 NVL72的14倍。Rubin过后,下一代的Feynman架构将于2028年面市。
风险提示:未来中美贸易摩擦可能进一步加剧,存在美国政府将继续加征关税、设置进口限制条件或其他贸易壁垒风险;宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险;全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。
09 通信视角下的新质生产力:科技自强,先进发展
新技术:科技创新,自立自强
新技术强调原创性、颠覆性科技创新,科技自立自强。随着当前科技领域自立自强的需求愈发强烈,无论是针对前沿性的技术创新,还是现有技术的国产化替代,都是迫在眉睫。从通信行业的视角来看,新技术主要包含人工智能与算力、量子技术和鸿蒙(操作系统)等。
2022年8月,美国首次针对中国实施大规模芯片出口制裁,停止出口A100和H100两款芯片和相应产品组成的系统,为满足合规要求,英伟达随后推出了面向中国市场的H800与A800,互联带宽被下调。2023年10月,BIS公布的先进计算芯片出口管制新规进一步扩大限制范围。新规去除了“互联带宽”作为判定是否受限的依据,并新增了“性能密度”与“总处理性能(TPP)”成为新的标准,使得A100、A800、H100、H800、L40、L40S、RTX 4090等多款产品遭到限制。虽然英伟达推出了符合新规的L20、L2和H20,但芯片的算力性能被迫遭到大幅下调。2024年11月,环球时报引述路透社10日报道称,美国商务部已致函台积电,要求其从11月11日起开始停止向中国大陆客户供应7纳米及更先进制程工艺的AI芯片。
北美云厂商持续加大对于人工智能领域的投资。2024Q3,北美四家云厂商的资本开支总计为588.62亿美元,同比增长59.31%,持续高速增长态势,且对未来资本开支指引乐观,重点投向AI算力基础设施建设。

人工智能是发展新质生产力的重要引擎。新质生产力由创新主导,人工智能是推动创新的核心数字能力,是发展新质生产力的重要引擎。2024年诺贝尔物理学奖、化学奖授予者均与AI相关。2024年3月国务院政府工作报告中:在谈到“科技创新实现新的突破”时,肯定了“关键核心技术攻关成果丰硕”,特别提到“人工智能、量子技术等前沿领域创新成果不断涌现”;在谈到大力推进现代化产业体系建设,加快发展新质生产力时,提出深化大数据、人工智能等研发应用,开展“人工智能+”行动,打造具有国际竞争力的数字产业集群。
国内人工智能算力基础设施投资也在持续加码。以腾讯、阿里巴巴两家云厂商为例,2023Q1资本开支开始呈现逐季度回暖态势,从23Q4开始同比转正,2024年以来较快增长。2024Q3,腾讯、阿里巴巴资本开支分别为170.94亿元、169.77亿元,分别同比增长114%、313%。

在海外的算力基础设施产业中,除芯片环节外,国内厂商在其他环节均有不同程度的参与,尤其在光模块领域占据主要市场份额,并在液冷、电源、铜连接等领域不断提升渗透率,未来主要关注需求增长、产品升级、新产品渗透等几个维度带来的业务增量;在国内的算力基础设施产业中,国产算力的应用比例将不断提升,产业链自身基本可以实现闭环,包括AI芯片、服务器、交换机、光模块、液冷、连接器/线束、PCB等各环节在内的国内公司都将集中受益,未来主要关注需求增长、芯片性能和供应能力提升、国产化比例增加等几个维度带来的业务增量。
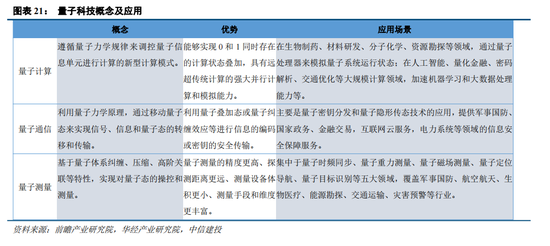
国家高度重视量子科技的发展,将其视为战略性领域。2021年至今,国家层面制定了相应的政策和规划,以推动量子科技的研究和应用。当前,在电信运营商的推动下,量子密话正加速向行业及个人客户拓展,尤其是华为Mate 60对外宣传量子密话功能后,量子通信在个人市场推广引发市场关注。我们预计量子密话的应用前期主要以政府、国防、公安、金融、电力等行业为主,但考虑到这些行业庞大的业务量及基层员工数量,若量子密话渗透率的提升将反向促进量子通信网络的建设。我们建议关注以下两个方向,一是QKD组网设备,直接受益于量子通信网络的建设;二是量子SIM卡领域,当前在手机等移动场景实现量子加密功能,通常是采用更换量子SIM卡的形式,且量子SIM卡价值量高于普通SIM卡(与内存大小相关,内存越大价格越贵)。
操作系统作为数字基础设施的底座,承担软硬件协同的关键角色。过去,全球操作系统市场基本被谷歌旗下的Android、微软旗下的Windows、苹果公司旗下的iOS与MacOS,以及Linux系统等垄断。自主可控的操作系统对国家安全和产业发展具有重要意义。鸿蒙是国产操作系统发展史上的重要里程碑,实现全栈自研。
目前,鸿蒙生态已经发展成为全球第三大、国内第二大移动应用生态。2024Q1,HarmonyOS在国内手机市场份额达到17%,首次超过ios系统跃居国内第二,全球手机市场份额也持续提升至4%。截止2024年6月,整个鸿蒙生态的设备数量已超过9亿,已有230万鸿蒙开发者投入到鸿蒙生态的开发中来。2023年8月,华为发布HarmonyOS NEXT开发者预览版,并启动了鸿蒙原生应用的开发。2024年10月,华为发布原生鸿蒙操作系统HarmonyOS NEXT,并且已上架1.5万个鸿蒙原生应用与元服务。我们认为,未来持续关注华为HarmonyOS的生态合作伙伴的相关业务进展,包括硬件(芯片、模组、硬件开发)、软件提供商、行业应用等环节。

风险提示:AI热点应用及变现能力不及预期可能导致AI算力投资快速回落,进而导致算力板块利润率、业绩预期明显下修;红利资产在估值修复后,可能因业绩增速下降、预期股息率下降或者筹码结构交易因素等导致估值、股价回落;国际环境变化对供应链的安全和稳定产生影响,对相关公司向海外拓展的进度产生影响;人工智能行业发展不及预期,影响云计算产业链相关公司的需求;低空经济行业发展进度不及预期;5G-A基站建设规模低于预期;低轨卫星星座建设成本居高不下,商业化落地进程受阻;市场竞争加剧,导致毛利率快速下滑;汇率波动影响外向型企业的汇兑收益与毛利率,包括ICT设备、光模块/光器件等板块的企业;数字经济和数字中国建设发展不及预期等;电信运营商的云计算业务发展不及预期;运营商资本开支不及预期;云厂商资本开支不及预期;通信模组、智能控制器行业需求不及预期等。
10 算力为基,自主可控大势所趋,Agent及B端应用崛起
国产AI芯片:25年值得期待,重视更可控、更具产品力的AI芯片
GPU具备图形渲染和并行计算两大核心功能。GPU具有数量众多的运算单元,适合计算密集、易于并行的程序,一般作为协处理器负责图形渲染和并行计算。对于国内来说,民用图形渲染领域买单的人是游戏爱好者,GPU公司需要跟大型游戏厂商进行适配合作,背后的生态支持需要大量工作。对于智算领域,生态要求极高,需要基础算子及应用程序算法的持续积累和优化,英伟达的CUDA具备绝对的生态优势,其次互联能力要求也极高,并且由于海外对国内使用先进制程有诸多限制,也限制了国内AI芯片的迭代。

我们认为国内AI芯片厂商能否脱颖而出,核心看以下三点:
出货量至关重要:国产AI训练芯片研发周期2年, 人员500人以上, 则需要人员费用500*80万*2=8亿, 7nm流片费用1500万美金, EDA、 IP数千万美元, 则一颗芯片整体投入约10亿。按照训练芯片单价7万, 毛利率50%测算, 则需要出货至少达到3万片才能分摊研发成本。
构建自主生态:兼容英伟达CUDA在短期可以减轻开发和迁移难度;长期来看,国产GPU如果完全依赖CUDA生态,硬件迭代将受英伟达的开发进程束缚。对于很多互联网大厂来说,自主生态的路会更长。
产品力:做产品而不是做项目,核心是互联网客户。

自动驾驶芯片:国产力量加速崛起
自动驾驶芯片以“CPU+GPU+NPU”的SoC异构方案为主,核心在NPU和ISP/DSP。传统的汽车电子芯片为MCU,多依赖于单一CPU处理器,但面对复杂的自动驾驶任务,CPU显得力不从心。目前自动驾驶芯片结构是以“CPU+GPU+NPU”的SoC异构方案为主,结合了通用计算、图形加速和专用加速的优势,能够高效处理自动驾驶中的海量数据和复杂算法,满足实时性和准确性的要求。自动驾驶芯片要完成瞬时处理、反馈、决策规划、执行的效果,对NPU算力要求非常高。自动驾驶级别每升高一级,对计算力的需求至少增加十倍。L2级别至少需要数十TOPS的算力,L3需要数百TOPS的算力,L4为数千TOPS。ISP是图像信号处理的核心芯片,负责前期的数据准备和图像预处理,以确保输入数据的质量;ISP生成的图像数据需要经过DSP进一步处理,DSP则可以进行更高级的图像处理,如目标检测、道路检测等应用。

英伟达代表全球自动驾驶芯片最顶尖水平。2023年9月,英伟达正式发布了智能汽车芯片Thor。Thor车载计算平台分为两个版本,分别是单片1000 TOPS算力版本,和双片共计2000 TOPS算力版本。最早于明年开始量产,同年上车。伴随着芯片架构升级,Thor平台将搭载专为Transformer、大语言模型和生成式AI工作负载而打造的全新Blackwell架构。相比于其他主流的智能驾驶芯片,Thor芯片性能具有代差优势。在AI算力上,Thor远高于其他主流芯片,从而实现驾舱融合;在制造工艺上,Thor采用4纳米的先进技术,有效降低功耗和成本,减少发热问题。目前Thor超级芯片仍处于研发阶段,计划于2025年量产,而其他厂商同期规划产品算力基本低于1000TOPS,Thor具有显著的代差优势。

外资芯片占比较高,自主厂商逐渐起量。根据盖世汽车的数据显示,2023年智驾域控芯片搭载量排名前四的分别是特斯拉FSD芯片、英伟达Orin、Mobileye EyeQ4H和Mobileye EyeQ5H,装机量分别为:1,208,402颗、1,147,311颗、201,437颗和175,246颗,对应市场份额分别为34.4%、32.6%、5.7%和5%。特斯拉FSD和英伟达Orin占比近七成。自主厂商也在不断突围。地平线、华为等厂商紧随英伟达、特斯拉其后,2023年地平线出货量20万颗,市占率为6.1%,位列第三,2024年上半年华为以10.5%市场份额位列第三。

Mobileye作为较早布局自动驾驶业务的芯片厂商,曾经是国内智能汽车首选的芯片厂商,但由于其“黑盒模式”以及整体性能扩展不如英伟达等厂商,因此一些厂商开始自研以及转向英伟达。但Mobileye在ADAS市场份额依旧有较大影响力,中国市场约占其业绩的1/3。外资Mobileye逐渐开始式微,其在中国的ADAS市场也被中国本土企业所蚕食。Mobileye二季度报告显示,全球多家OEM大幅下调了今年下半年的产量预期,中国区市场下半年订单有所下降。

风险提示:北美经济衰退预期逐步增强,宏观环境存在较大的不确定性,国际环境变化影响供应链及海外拓展;芯片紧缺可能影响相关公司的正常生产和交付,公司出货不及预期;信息化和数字化方面的需求和资本开支不及预期;市场竞争加剧,导致毛利率快速下滑;主要原材料价格上涨,导致毛利率不及预期;汇率波动影响外向型企业的汇兑收益与毛利率;大模型算法更新迭代效果不及预期,可能会影响大模型演进及拓展,进而会影响其商业化落地等;汽车与工业智能化进展不及预期等。
11 AI端侧应用兴起,国产高端芯片亟需国产化
AI引领半导体周期,国产高端芯片亟需突破
2.1 处理器:高端芯片进口受限,国产供应链亟需突破
英伟达、AMD对华供应高端GPU芯片进一步受限。2022年,美国BIS实施出口管制,英伟达和AMD的高端GPU产品出口受到限制。为满足合规要求,英伟达随后推出了面向中国市场的H800与A800,互联带宽被下调。2023年,BIS公布的先进计算芯片出口管制新规进一步扩大限制范围。新规去除了“互联带宽”作为判定是否受限的依据,并新增了“性能密度”与“总处理性能(TPP)”成为新的标准,使得A100、A800、H100、H800、L40、L40S等多款产品遭到限制。虽然英伟达推出了符合新规的L20、L2和H20,但新品的算力性能被迫遭到大幅下调。

国产算力芯片迎来国产替代窗口期。考虑到英伟达新品将迎来大幅性能升级,并面向中国市场禁售,国产算力芯片发展刻不容缓。当前已经涌现出一大批国产算力芯片厂商,昇腾、寒武纪相继推出自研AI芯片,海光信息的DCU也逐渐打出知名度,其他配套环节的国产化进程也正在加速推进。
昇腾310与昇腾910构成华为昇腾产业链的算力基座,打造全场景AI基础设施方案。昇腾310与昇腾910均基于华为自研达芬奇3D Cube技术,集成了张量、矢量、标量等多种运算单元,支持多种混合精度计算。昇腾310是华为首款全栈全场景人工智能芯片,具备低功耗优势,昇腾910支持云边端全栈全场景应用。昇腾已基于310和910形成了完善的解决方案,出货形态包括:包括Atlas系列模块、板卡、小站、服务器、集群等,打造面向“端、边、云”的全场景AI基础设施方案,覆盖深度学习领域推理和训练全流程。

昇腾AI大模型训推一体化解决方案,加速国产大模型落地。2023世界人工智能大会(WAIC)期间,华为主办的昇腾人工智能产业高峰论坛于7月6日在上海召开。华为携手伙伴联合发布昇腾AI大模型训推一体化解决方案,加速大模型在各行业应用落地,并有23家昇腾AI伙伴推出AI服务器、智能边缘与终端新品,共同为行业智能化升级提供丰富的产品与解决方案。

寒武纪专注AI领域核心处理器,思元590采用全新架构,性能相比在售旗舰有大幅提升。寒武纪目前已推出了思元系列智能加速卡,第三代产品思元370基于7nm制程工艺,是寒武纪首款采用chiplet技术的AI芯片,最高算力达到256 TOPS(INT8)。思元370还搭载了MLU-Lin多芯互联技术,互联带宽相比PCIe 4.0提升明显。在2022年9月1日举办的WAIC上,寒武纪陈天石博士介绍了全新一代云端智能训练芯片思元590,思元590采用MLUarch05全新架构,实测训练性能较在售旗舰产品有了大幅提升,能提供更大的内存容量和更高的内存带宽,其IO和片间互联接口也较上代实现大幅升级。

海光信息二代DCU升级规划稳步推进,海光DCU兼容类“CUDA”环境,适配性好。海光信息深算一号DCU产品目前已实现商业化应用。2020年1月,公司启动了第二代DCU深算二号的产品研发工作,研发工作进展正常。海光DCU协处理器全面兼容ROCm GPU计算生态,由于ROCm和CUDA在生态、编程环境等方面具有高度的相似性,理论上讲,市场上规模最大的GPGPU开发群体——CUDA用户可用较低代价快速迁移至ROCm平台,有利于海光DCU的市场推广。同时,由于ROCm生态由AMD提出,AMD对ROCm生态的建设与推广也将有助于开发者熟悉海光DCU。

2.2 存储:价格因库存因素短期承压,看好2025年AI终端提振需求
复盘存储器历史,存储器周期大致4-5年,上行、下行周期大致2年上下。上轮周期起始于2020Q1,2021Q3存储器价格见顶,此后价格持续下滑,至2023Q2持续7个季度。本轮周期,存储器2023Q3开始涨价,合约价上涨至2024Q3,现货价上涨至2024Q2,当前因为前期客户端、渠道端备货较多,库存在持续消化。从高频数据看,当前4Gb DDR3现货价、8Gb DDR4合约价等数据转跌,DDR5的价格相对坚挺,台股DRAM月度营收同比增速有所回落,存储周期来到后半程。

供给端:当前产能供给充足,产能结构性升级。DRAM和NAND Flash原厂稼动率处于高位,当前供应充足。结构上,先进产能淘汰落后产能。一方面,DDR5升DDR4降,SK海力士近期表示将会把DDR4的产能从6月的40%、9月的30%降低至年底的20%,三星电子也将DDR4的产能转移至DDR5和LPDDR5。另一方面,原厂纷纷针对现有产能改线升级,工艺制程继续推进,例如三星电子计划在2024年内推出1c nm制程DDR内存,该节点可提供32Gb颗粒容量产品,而在2026年将推出其最后一代10nm级工艺1d nm,仍最大提供32Gb容量。2027年,三星将突入10nm以下级DRAM制程节点,发布0a nm工艺的DDR内存产品,同时该节点的内存单颗粒容量将来到更高的48Gb。
需求端:笔电手机新机发布、服务器需求强劲,AI终端驱动存储成长。根据Trendforce统计,2023年服务器、手机、笔电的出货量分别增长-5.9%、-3.1%、-13.2%,预计2024年分别增长2.3%、2.9%、2.1%,呈现弱复苏态势,我们判断2025年手机、PC继续恢复,服务器维持强劲增长。(1)服务器:AI服务器持续高增长,2024年底DDR5渗透率预计达到60%,2025年进一步提升。而2025年CSP资本开始将维持高增长,AI服务器需求强劲,拉动HBM、DDR5、大容量SSD需求。(2)手机:24Q4发布的荣耀Magic7、小米15、vivo X200等安卓旗舰机普遍搭载高通骁龙8系列最新处理器,融入更强的AI算力,通用大模型和垂类大模型进入手机,对应地,旗舰手机内存容量从过往两年的6/8GB升级至12/16GB,闪存容量从过往的256/512GB升级至512GB/1TB,配置大幅度提升,拉动存储需求。(3)笔电:微软将于2025年停止Windows 10的更新,另外2020-2021年疫情刺激的笔电需求也将于2024-2025年迎来换机需求,AI PC有望刺激PC市场重启成长。总而言之,当前存储的核心需求有短暂波动,但AI的引入刺激了终端配置升级需求,2025年AI服务器、AI 手机、AI PC渗透率进一步提升,存储需求有望保持高增长。
价格展望:由于通用服务器需求复苏,以及手机、PC客户的备货,2024Q3 DRAM均价持续上行。但随着备货完成,下游进入阶段库存消化,存储器价格在24Q4承压,Trendforce预计DRAM价格分化,HBM继续涨价,DDR5维持稳定,DDR4、DDR3降价,整体DRAM仍有0-5%的涨价;NAND方面,wafer、eMMC、UFS、Client SSD价格下降,企业级SSD维持涨价,整体NAND开始降价3-8%。展望2025年,预计2025年上半年库存去化完成,下半年存储器价格取决于需求侧AI终端的渗透情况。

2.3 设备及零部件:本土竞争力加强,国产化率大幅提升
2.3.1 设备:未来三年全球300mm设备支出达到4000亿,中国大陆支出占四分之一
未来三年全球半导体行业300mm晶圆厂设备投资达到4000亿美元,2025年设备支出将加速。SEMI发布《300mm晶圆厂2027年展望报告》指出,从2025年到2027年,全球300mm晶圆厂设备支出预计将达到创纪录的4000亿美元。强劲的支出是由半导体晶圆厂的区域化以及数据中心和边缘设备对AI芯片日益增长的需求推动的。2024年,全球300mm晶圆厂设备支出预计将增长4%,达到993亿美元,到2025年将进一步增长24%,首次突破1000亿美元,达到1232亿美元。
中国大陆资本支出占全球四分之一,全球Foundry设备支出约2300亿美元。从区域增长来看,预计到2027年,中国将保持全球300mm设备支出第一的地位,未来三年将投资超过1000亿美元。然而,SEMI预计投资将从2024年的450亿美元峰值逐渐减少到2027年的310亿美元。从领域增长来看,2025年至2027年间,Foundry设备支出预计将达到约2300亿美元;Logic和Micro领域预计将在未来三年率先扩大设备支出,预计总投资为1730亿美元;Memory位居第二,预计同期将贡献超过1200亿美元的支出,标志着另一个细分市场增长周期的开始。在Memory领域,DRAM相关设备的投资预计将超过750亿美元,而3D NAND的投资预计达到450亿美元。Power相关领域排名第三,预计未来三年投资将超过300亿美元,其中化合物半导体项目投资约140亿美元。同期,模拟和混合信号领域预计将达到230亿美元,其次是光电/传感器,为128亿美元。

存货为在手订单的“晴雨表”,反映半导体设备的高景气度。半导体设备的存货主要包括原材料、在产品、库存商品、发出商品、低值易耗品等。由于从获得订单到产品验收时间较长(一般跨年交付),存货的增长反应公司在手订单的增加,后续随着商品验收完成,将直接反映到公司的收入。
在我们梳理的17家半导体设备厂商中,截止2024Q3期末,龙头存货达到232亿,同比增长34%,存货同比增长117%,和存货同比增长分别为91%、83%。半导体行业存在供应链不稳定风险,进口原材料采购周期延长,半导体设备厂商增加原材料库存。其中,中微公司在订单增长下采购原材料,大量生产机台以向客户付运机台,导致存货余额增长。截止2024Q1期末公司发出商品余额19.23亿元,较期初余额的8.68亿元增长10.55亿元,为后续的收入实现打下良好基础。

合同负债是在手订单的直接指标,反映业绩增长能力。在我们梳理的17家半导体设备厂商中,前道设备厂商合同负债与收入增长加强,后道设备厂商受消费市场需求趋于稳定、存储器市场回暖、人工智能与高性能计算等热点应用领域带动等因素作用,以及封测厂商稼动率提升的影响,业绩逐步迎来反转。截止2024Q3期末,中微公司、京仪装备、、、合同负债同比增长较快,分别为119%、86%、77%、71%、68%,反应在手订单同比快速增长。中微公司合同负债达30亿元,公司新增订单76.4亿元,同比增长约52.0%。其中刻蚀设备新增订单62.5亿元,同比增长约54.7%;LPCVD新增订单3.0亿元,新产品开始启动放量。


存货与合同负债之和直观反映未来业绩增长确定性。在我们梳理的17家半导体设备厂商中,截至2024Q3期末,京仪装备和中微公司的存货与合同负债之和分别达到108%、98%,业绩增长确定性最强,对应的2024年Wind一致预期收入增长分别为41%、35%;其次拓荆科技、、存货与合同负债之和同比增长超过40%,分别为45%、99%、48%。

半导体设备业绩确定性强,未来下游需求增量带来巨大市场。根据Wind(申万行业分类)半导体设备季度数据,2021Q1-2024Q3期间,营收增长率和EPS增长率呈现由波峰转波谷,波谷逐步反弹趋势,波谷均产生在2023Q3,分别为25.1%、-25.4%,目前处在反弹中,其中在2024Q3,EPS增长率显著提升,代表半导体设备盈利能力进一步加强。
2.3.2 零部件:本土供应能力持续提升,纷纷扩产应对国产化需求
核心零部件是半导体产业链的基石。半导体核心零部件组建了半导体设备的核心子系统,决定半导体产品的成本与性能,市场规模约300亿美元。半导体设备零部件具有高精密、高洁净、耐腐蚀能力、耐击穿电压等特性,生产工艺涉及精密机械制造、工程材料、表面处理特种工艺、电子电机整合及工程设计等多个领域和学科,半导体设备的升级迭代很大程度上有赖于零部件的技术突破。因此,核心零部件不仅是半导体设备制造中难度较大、技术含量较高的环节之一,也是国内半导体设备企业的“卡脖子”的环节之一。

从市场竞争格局来看,零部件供应主要被美国、日本垄断。IC World 2020公开的20类半导体核心零部件产品的44家主要供应商中,存在20家美国供应商、16家日本供应商、2家德国供应商、2家瑞士供应商、2家韩国供应商、1家英国供应商,均为境外供应商,且以美国和日本为主。对全球主要半导体零部件企业(不含光刻机零部件)的半导体收入进行统计,美国半导体零部件企业的合计收入占比44%;日本半导体零部件企业的合计收入占比33%;英国、瑞士等欧洲地区占比21%;新加坡、韩国等半导体零部件企业的合计收入占比2%。

核心零部件进口依赖性高。芯谋研究数据显示,目前国产化率超过10%的半导体零部件有石英、反应喷淋头、边缘环等少数几类,其余国产化程度较低,尤其是各种阀门、真空计、O-ring密封圈等几乎完全依赖进口。其中,阀门(Valve)零部件的需求占总零部件需求的9%,但自给率却不足1%。因此在市场需求强劲,但国内供应商基本为空白的形势下,零部件采购周期拉长倒逼零部件的进口替代需求迫切。

针对不同类型的零部件,技术难点各不相同,国产化率差异大。机械类零部件应用最广,市场份额最大,主要产品技术已实现突破和国产替代。机电一体类和气液传输/真空系统零部件国内部分产品已实现技术突破,但产品稳定性和一致性与国外有差距。技术难度相对比较高的为电气类、仪器仪表类、光学类零部件,国内企业的电气类核心模块(射频电源等)主要应用于光伏、LED等泛半导体设备,高端产品尚未国产化;仪器仪表类对测量精度要求高,国内自研产品少量用于国内设备厂商,国产化率低,高端产品尚未国产化;光学类零部件对光学性能要求极高,由于光刻设备国际市场高度垄断,高端产品一家独大,国内光刻设备尚在发展,相应配套光学零部件国产化率低。

2.4 材料:半导体材料复苏强劲,国产化进一步加持
国内半导体材料需求持续高增,全球占比大幅提升。根据TECHCET数据及预测,全球半导体材料将在2024年同比增长近7%达到740亿美元;预计2027年市场规模将达到870亿美元以上。半导体材料主要分为晶圆制造材料和封装材料。根据SEMI数据,2023年,受整个半导体行业环境影响,全球半导体材料市场销售额下8.2%至667亿美元。从材料大类来看,2023年全球晶圆制造材料和封装材料的销售额分别为415亿美元和252亿美元,占全球半导体材料销售额的比重分别约62%和38%;从地区分布来看,中国台湾和中国大陆是全球前两大半导体材料消费地区,2023年销售额分别为192亿美元和131亿美元,占全球半导体材料销售额的比重分别约29%和20%,其中中国大陆是2023年全球唯一实现半导体材料销售额同比增长的地区。

今年以来半导体材料强劲反弹三个季度,电子化学品震荡反弹向上。根据Wind(申万行业分类)半导体设备季度数据,2021Q1-2024Q3期间,营收增长率和EPS增长率呈现由波峰转波谷,波谷逐步反弹趋势,半导体材料波谷产生在2023Q3,增长率分别为-2.8%、-34.1%,电子化学品波谷产生在2023Q3和2023Q4之间,今年以来半导体材料与电子化学品处在逐步复苏放量中。随着新建产线对材料需求持续扩大,国产化率提升,半导体产业复苏,半导体材料迎来长景气周期,另外,随着以HPC、AI和5G通信等为代表的需求牵引,先进封装领域的发展正在加速。
半导体材料与电子化学品复苏放量显著,业绩出现结构性的分化。对比2024Q3业绩,抛光垫=抛光液>靶材>化学品/光刻胶>封装材料>光掩膜版>硅片,呈现业绩分化。其中,CMP抛光垫,前三季度累计实现产品销售收入5.23亿元,同比增长95%;第三季度实现产品销售收入2.25亿元,环比增长38%,同比增长90%,再创历史单季收入新高。公司于今年9月首次实现抛光垫单月销量破3万片的历史新高,产品在国内市场的渗透程度随订单增长稳步加深,产品稳定性得到持续肯定。的靶材和零部件,在第二季度单季度实现8.55亿元,超高纯靶材和精密零部件均创历史新高,第三季度营收同比增长52.48%,环比增长16.69%。
封装材料贯穿了电子封装技术的多个技术环节,是半导体行业的先导产业。近年来,以HPC、AI和5G通信等为代表的需求牵引,正加速先进封装领域的发展。Yole数据显示,全球先进封装市场规模将从2023年的378亿美元增长至2029年的695亿美元,期间的复合年增长率为10.7%。先进封装材料的代表企业主要为、。其中,联瑞新材聚焦高端芯片(AI、5G、HPC等)封装、异构集成先进封装(Chiplet、HBM等)、新一代高频高速覆铜板(M7、M8等)、新能源汽车用高导热界面材料、先进毫米波雷达和光伏电池胶黏剂等下游应用领域的先进技术,持续推出多种规格低CUT点Lowα微米/亚微米球形硅微粉、球形氧化铝粉,高频高速覆铜板用低损耗/超低损耗球形硅微粉。华海诚科专注于向客户提供更有竞争力的环氧塑封料与电子胶黏剂产品,构建了可应用于传统封装(包DIP、TO、SOT、SOP等)与先进封装(QFN/BGA、SiP、FC、FOWLP/FOPLP等)的全面产品体系,可满足下游客户日益提升的性能需求。


风险提示:1、未来中美贸易摩擦可能进一步加剧,存在美国政府将继续加征关税、设置进口限制条件或其他贸易壁垒风险;2、AI上游基础设施投入了大量资金做研发和建设,端侧尚未有杀手级应用和刚性需求出现,存在AI应用不及预期风险;3、宏观环境的不利因素将可能使得全球经济增速放缓,居民收入、购买力及消费意愿将受到影响,存在下游需求不及预期风险;4、大宗商品价格仍未企稳,不排除继续上涨的可能,存在原材料成本提高的风险;5、全球政治局势复杂,主要经济体争端激化,国际贸易环境不确定性增大,可能使得全球经济增速放缓,从而影响市场需求结构,存在国际政治经济形势风险。
12 机械行业2025年投资策略:聚焦泛科技、存量更新与出海
半导体设备:海外制裁边际收紧,紧跟自主可控主旋律
全球半导体市场见底回升
Gartner和SEMI预计2024年开始全球半导体设备市场回升。根据Gartner预测,预计全球晶圆厂投资2023年下滑10%至1635亿美金,2024年开始重新恢复正增长。根据SEMI预测,全球半导体设备市场在2024-2025年出现回升,分别约1053、1241亿美元,同比分别+4.4%、+17.9%。随着半导体市场筑底回升,2024年全球晶圆厂资本开支有望回暖,带动设备规模增长。

IC Insights预测2024年下游核心半导体制造企业资本开支同比略降,其中存储表现更好。大部分半导体制造企业对2024年持谨慎态度,认为是行业触底回升的调整之年,2024年全球半导体资本开支约为1650亿美金,同比下降约2%。随着内存市场复苏以及AI等新应用预计将增加需求,主要存储公司普遍会在2024年增加资本支出,因此行业中存储板块2024年资本开支预期相对乐观,预计2024年达546亿美金,同比提升4%;此外,代工及IDM资本开支预计同比将分别出现6%、4%的下滑。


综合以上,我们判断2024年全球半导体设备市场处于见底回升的过程,2025年整体复苏预期更强。
外部制裁边际收紧背景下,紧跟自主可控主旋律
外部制裁边际收紧,如9月BIS新规修订、11月美国半导体设备制造商要求供应商替换中国组件等,在此背景下,我们坚定认为要紧跟自主可控的行业主旋律。①9月6日,BIS发布出口管制新规,重在控制和GAAFET结构“开发”和“生产”相关技术,此外,新规还对用于制造高深宽比结构的各向异性干法刻蚀设备加码管制;②同日,荷兰政府规定从2024年9月7日起,ASML在出口相关先进制造设备时必须申请授权,将需要向荷兰政府而非美国政府申请TWINSCAN NXT:1970i和1980i型号浸没式DUV光刻系统的出口许可证。美国BIS新规主要影响HBM相关产线及国产128层闪存(如3D NAND闪存);荷兰政府相关规定将对光刻机的限制延伸到1980及以下型号,但许可受理权在荷兰政府而非美国政府,或对中国进口光刻机影响有限,但核心设备光刻机的自主可控也迫在眉睫。③11月美国政府要求供应商替换中国组件,零部件向海外供应难度增大。2024年11月4日,在美国政府最新指令下,半导体设备制造商AMAT和Lam Research等要求供应商替换中国组件,并禁止供应商有中国投资者或股东。
国内市场来看,制裁后中国大陆地区加大对进口设备的囤货,后续国内扩产向上预期较强,尤其是对国产设备的招标。海外设备公司中国大陆地区营收连续高增,尤其核心环节光刻机,2024Q3 ASML来自中国大陆营收27.85亿欧元,同比+14%,再创历史新高,连续五个季度成为公司第一大收入来源地,我们预计ASML中国大陆地区营收连续几个季度高增主要系制裁后中国客户的囤货性需求增加,后续将展开对国产设备的相关招标。
半导体设备国产化水平加速提升。我们结合SEMI与电子专用设备协会数据进行测算,以SEMI公布的中国大陆半导体设备市场规模作为分母,以电子专用设备协会公布的国产厂商IC设备销售额作为分子,测算得到国内半导体设备国产化率从2018年的4.91%提升至2023年的19.92%,呈现持续攀升的趋势,预计后续仍将继续提升。

2024年前三季度板块营收高速增长,订单支撑强劲
板块营收高速增长,利润受确认收入节奏与高额研发费用影响。设备整机板块来看,2024Q1-Q3半导体设备整机营收达420.71亿元,同比增长34%;毛利率44.63%,同比+0.38pct;归母净利润达78.02亿元,同比增长20%。零部件板块来看,2024Q1-Q3设备零部件营收达111.05亿元,同比增长28%;毛利率29.86%,同比-0.04pct;归母净利润12.05亿元,同比增长14%。板块内企业营收均维持高速增长,但近期国产设备企业配合下游客户进行先进制程并加大新产品研发,研发费用大幅提升,对利润有所影响。
板块订单支撑强劲,后续业绩值得期待。半导体设备整机板块来看,2024Q3末板块合同负债达201.82亿元,同比增长13.99%;存货达576.12亿元,同比增长42.81%。半导体设备零部件板块来看,2024Q3末板块合同负债达38.41亿元,同比增长4.06%;93.50亿元,同比增长7.39%。设备整机合同负债稳步增长,存货增速较高,部分公司同比下滑主要系结构影响,如北方华创今年预付款比例较高的光伏设备订单有所下滑,影响了合同负债。但整体来看半导体设备订单在2023年同期基数相对较高的背景下依然实现较快增长,后续业绩支撑强劲,零部件板块由于交期更短、确收节奏更快,合同负债和存货均实现小幅增长。
投资建议:外部制裁虽然边际收紧,国内也加紧半导体产业攻关,大基金三期出台,将重点支持先进制程突破,拉动设备需求并加快卡脖子设备的攻关进度,预计设备国产化率将持续提升。国内下游扩产持续向上+国产化设备验证持续推进,国产设备公司订单增长维持较好趋势,板块整体基本面向好。
风险提示:①宏观经济和制造业景气度下滑风险:机器人产业链公司受宏观经济波动影响较大,行业与宏观经济波动的相关性明显,尤其是和工业制造的需求、基础设施投资等宏观经济重要影响因素强相关。若未来国内外宏观经济环境发生变化,下游行业投资放缓,将可能影响机器人产业链的发展环境和市场需求。②供应链波动风险:受全球宏观经济、贸易战、自然灾害等影响,若原材料紧缺,芯片等关键物料供应持续出现失衡,将引起机器人零部件制造业厂商生产成本增加甚至无法正常生产,经营业绩可能会受影响。③研发进展不及预期风险:目前,机器人领域,尤其是人形机器人领域,研发仍然面临较多的困难和不确定性。
报告来源

证券研究报告名称:《美光存储涨价并暂停报价,Meta发布新款AR眼镜》
对外发布时间:2025年9月21日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC 编号:S1440520070002
郭彦辉 SAC 编号:S1440520070009
证券研究报告名称:《周报:商务部对原产于美国的进口相关模拟芯片发起反倾销调查》
对外发布时间:2025年9月14日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC编号:S1440520070002
何昱灵 SAC编号:S1440524080001
证券研究报告名称:《电子行业2025半年报综述:上半年业绩亮眼,下半年AI持续驱动增长》
对外发布时间:2025年9月11日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC 编号:S1440520070002
SFC 编号:BNU539
郭彦辉 SAC 编号:S1440520070009
何昱灵 SAC 编号:S1440524080001
赵子鹏 SAC 编号:S1440523080001
章合坤 SAC 编号:S1440522050001
证券研究报告名称:《周报:Sandisk宣布涨价10%,华为发布会推出麒麟9020芯片》
对外发布时间:2025年9月7日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC编号:S1440520070002
郭彦辉 SAC 编号:S1440520070009
证券研究报告名称:《AI新纪元:砥砺开疆・智火燎原》
对外发布时间:2025年7月24日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
黄文涛 SAC 编号:S1440510120015
SFC 编号:BEO134
阎贵成 SAC 编号:S1440518040002
SFC 编号:BNS315
程似骐 SAC 编号:S1440520070001
SFC 编号:BQR089
崔世峰 SAC 编号:S1440521100004
SFC 编号:BUI663
贺菊颖 SAC 编号:S1440517050001
SFC 编号:ASZ591
黎韬扬 SAC 编号:S1440516090001
刘双锋 SAC 编号:S1440520070002
刘永旭 SAC 编号:S1440520070014
SFC 编号:BVF090
庞佳军 SAC 编号:S1440524110001
陶亦然 SAC 编号:S1440518060002
王在存 SAC编号:S1440521070003
许琳 SAC 编号:S1440522110001
SFC 编号:BVU271
许光坦 SAC 编号:S1440523060002
杨艾莉 SAC 编号:S1440519060002
SFC 编号:BQI330
叶乐 SAC 编号:S1440519030001
SFC 编号:BOT812
应瑛 SAC 编号:S1440521100010
SFC 编号:BWB917
于芳博 SAC 编号:S1440522030001
SFC 编号:BVA286
袁清慧 SAC编号:S1440520030001
SFC编号:BPW879
赵然 SAC 编号:S1440518100009
SFC 编号:BQQ828
朱玥 SAC 编号:S1440521100008
SFC 编号:BTM546
证券研究报告名称:《周报:关注中美关税政策对半导体、消费电子产业链的影响》
对外发布时间:2025年4月6日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC编号:S1440520070002
何昱灵 SAC编号:S1440524080001
证券研究报告名称:《周报:美光发布涨价函,存储价格有望逐步回升》
对外发布时间:2025年3月31日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC编号:S1440520070002
何昱灵 SAC编号:S1440524080001
证券研究报告名称:《周报:GTC 2025发布Blackwell Ultra,并更新Rubin架构细节》
对外发布时间:2025年3月23日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC编号:S1440520070002
何昱灵 SAC编号:S1440524080001
证券研究报告名称:《通信行业2025年投资策略报告:通信视角下的新质生产力:科技自强,先进发展》
对外发布时间:2024年11月25日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘永旭 SAC 编号:S1440520070014
SFC 编号:BVF090
阎贵成 SAC 编号:S1440518040002
SFC 编号:BNS315
武超则 SAC 编号:S1440513090003
SFC 编号:BEM208
杨伟松 SAC 编号:S1440522120003
汪洁 SAC 编号:S1440523050003
曹添雨 SAC 编号:S1440522080001
尹天杰 SAC 编号:S1440524070016
证券研究报告名称:《人工智能2025年投资策略报告:算力为基,自主可控大势所趋,Agent及B端应用崛起》
对外发布时间:2024年11月25日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
于芳博 SAC 编号:S1440522030001
方子箫 SAC 编号:S1440524070009
辛侠平 SAC 编号:S1440524070006
证券研究报告名称:《电子行业2025年投资策略展望:AI端侧应用兴起,国产高端芯片亟需国产化》
对外发布时间:2024年11月25日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
刘双锋 SAC 编号:S1440520070002
庞佳军 SAC 编号:S1440524110001
范彬泰 SAC 编号:S1440521120001
孙芳芳 SAC 编号:S1440520060001
乔磊 SAC 编号:S1440522030002
章合坤 SAC 编号:S1440522050001
郭彦辉 SAC 编号:S1440520070009
王定润 SAC 编号:S1440524060005
何昱灵 SAC 编号:S1440524080001
证券研究报告名称:《机械行业2025年投资策略:聚焦泛科技、存量更新与出海》
对外发布时间:2024年11月28日
报告发布机构:中信建投证券股份有限公司
本报告分析师:
吕娟 SAC 编号:S1440519080001
SFC 编号:BOU764
许光坦 SAC 编号:S1440523060002
李长鸿 SAC 编号:S1440523070001
陈宣霖 SAC 编号:S1440524070007
籍星博 SAC 编号:S1440524070001
杨超 SAC 编号:S1440524070003

重要提示及免责声明
重要提示:
通过本订阅号发布的观点和信息仅供中信建投证券股份有限公司(下称“中信建投”)客户中符合《证券期货投资者适当性管理办法》规定的机构类专业投资者参考。因本订阅号暂时无法设置访问限制,若您并非中信建投客户中的机构类专业投资者,为控制投资风险,请您请取消关注,请勿订阅、接收或使用本订阅号中的任何信息。对由此给您造成的不便表示诚挚歉意,感谢您的理解与配合!
免责声明:
本订阅号(微信号:中信建投证券研究)为中信建投证券股份有限公司(下称“中信建投”)研究发展部依法设立、独立运营的唯一官方订阅号。
本订阅号所载内容仅面向符合《证券期货投资者适当性管理办法》规定的机构类专业投资者。中信建投不因任何订阅或接收本订阅号内容的行为而将订阅人视为中信建投的客户。
本订阅号不是中信建投研究报告的发布平台,所载内容均来自于中信建投已正式发布的研究报告或对报告进行的跟踪与解读,订阅者若使用所载资料,有可能会因缺乏对完整报告的了解而对其中关键假设、评级、目标价等内容产生误解。提请订阅者参阅中信建投已发布的完整证券研究报告,仔细阅读其所附各项声明、信息披露事项及风险提示,关注相关的分析、预测能够成立的关键假设条件,关注投资评级和证券目标价格的预测时间周期,并准确理解投资评级的含义。
中信建投对本订阅号所载资料的准确性、可靠性、时效性及完整性不作任何明示或暗示的保证。本订阅号中资料、意见等仅代表来源证券研究报告发布当日的判断,相关研究观点可依据中信建投后续发布的证券研究报告在不发布通知的情形下作出更改。中信建投的销售人员、交易人员以及其他专业人士可能会依据不同假设和标准、采用不同的分析方法而口头或书面发表与本订阅号中资料意见不一致的市场评论和/或观点。
本订阅号发布的内容并非投资决策服务,在任何情形下都不构成对接收本订阅号内容受众的任何投资建议。订阅者应当充分了解各类投资风险,根据自身情况自主做出投资决策并自行承担投资风险。订阅者根据本订阅号内容做出的任何决策与中信建投或相关作者无关。
本订阅号发布的内容仅为中信建投所有。未经中信建投事先书面许可,任何机构和/或个人不得以任何形式转发、翻版、复制、发布或引用本订阅号发布的全部或部分内容,亦不得从未经中信建投书面授权的任何机构、个人或其运营的媒体平台接收、翻版、复制或引用本订阅号发布的全部或部分内容。版权所有,违者必究。
新浪声明:此消息系转载自新浪合作媒体,新浪网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。



